how_cpp_20_changes_the_way_we_write_code
How C++20 Changes the Way We Write Code - Timur Doumler
-
Comparative Growth of C++ Standards:
- C++11 introduced a significant number of pages to the standard, more so than C++20.
- C++17 added slightly more pages than C++20.
- Many C++17 library features were already available in Boost, such as File System, Any, Optional, and Variant.
-
Core Language Features in C++17:
- Included structured bindings and class template argument deduction.
- Considered by some as syntactic sugar, facilitating shorter ways to express already possible code constructs.
-
Fundamental Changes in C++20:
- Introduced features that fundamentally alter how programmers conceptualize and write code.
- Focuses on enhancing the mental model of functions, template writing, library design, and code compilation and organization.
-
Significance of C++20:
- Argued to be the most significant update in the history of C++.
- Highlighted by the introduction of major features: Coroutines, Concepts, Ranges, and Modules
- These features are seen as transformative, changing both the structure and the conceptual approach to C++ programming.
Coroutine
-
Traditional Function Model:
- Functions are blocks of code with a name, parameters, local variables, and a return value.
- This model has remained largely unchanged since the 1950s, where functions were referred to as subroutines.
-
Limitations of Pure Functions:
- Pure functions always return the same output for given inputs.
- Example: A function
fthat always returns zero is predictable and lacks flexibility in producing varied outputs.
-
Generating Variable Output Sequences:
- Simple loop in the
mainfunction can generate a sequence like 0, 1, 2, 3. - Separating sequence generation from printing improves design and modularity but usually involves storing the entire sequence in memory.
- Simple loop in the
-
Challenges with Procedural Approach:
- Storing large sequences (e.g., from 0 to 1 billion) is impractical and inefficient.
- Ideal solution: lazily generate each number as needed without pre-storing the entire sequence.
int f() {
static int i = 0;
return i++;
}
int main() {
std ::cout << f() << '\n';
std ::cout << f() << '\n';
std ::cout << f() << '\n';
}- Object-Oriented Approach:
- Implementing a class to encapsulate the generation logic using member variables and methods.
- Although effective, this approach may be considered overkill for simple sequence generation, introducing unnecessary complexity.
class my_generator {
int i = 0;
public:
int operator()() { return i++; }
};
int main() {
my_generator g;
std ::cout << g() << '\n';
std ::cout << g() << '\n';
std ::cout << g() << '\n';
}- Use of Lambdas and Init Capture:
- Lambdas with init capture (introduced in C++14) simplify the object-oriented approach but still maintain explicit state.
- This method still mirrors object-oriented thinking, albeit with syntactic simplifications.
int main() {
auto g = [i = 0]() mutable { return i++; };
std ::cout << g() << '\n';
std ::cout << g() << '\n';
std ::cout << g() << '\n';
}-
Introduction of Coroutines:
- Coroutines extend the traditional function model by allowing functions to yield intermediate values and pause execution.
- Upon subsequent calls, coroutines resume from the last yield point, maintaining their local state without needing explicit object-like state management.
- This concept, while old (described in the 1960s), was only recently incorporated into C++, significantly enhancing the language's capability to manage stateful computations more intuitively.
-
Revolutionizing Sequence Generation:
- Coroutines provide a more natural and efficient way to generate sequences on-the-fly, altering the traditional and object-oriented approaches by simplifying state management and control flow.
- This shift in paradigm allows for more dynamic and flexible coding practices, suitable for modern programming challenges.
-
Simplifying Function Logic with Coroutines:
- Coroutines expand the concept of functions by allowing state retention and re-entry at specific points, greatly simplifying complex operations like generating sequences dynamically.
-
C++ Implementation of Coroutines:
- Unlike other languages that use the keyword
yield, C++ usesco_yieldto manage state within coroutines due to specific language design choices.
- Unlike other languages that use the keyword
// conceptually
int f() {
int i = 0;
while (true) co_yield i++;
}
int main() {
std ::cout << f() << '\n';
std ::cout << f() << '\n';
std ::cout << f() << '\n';
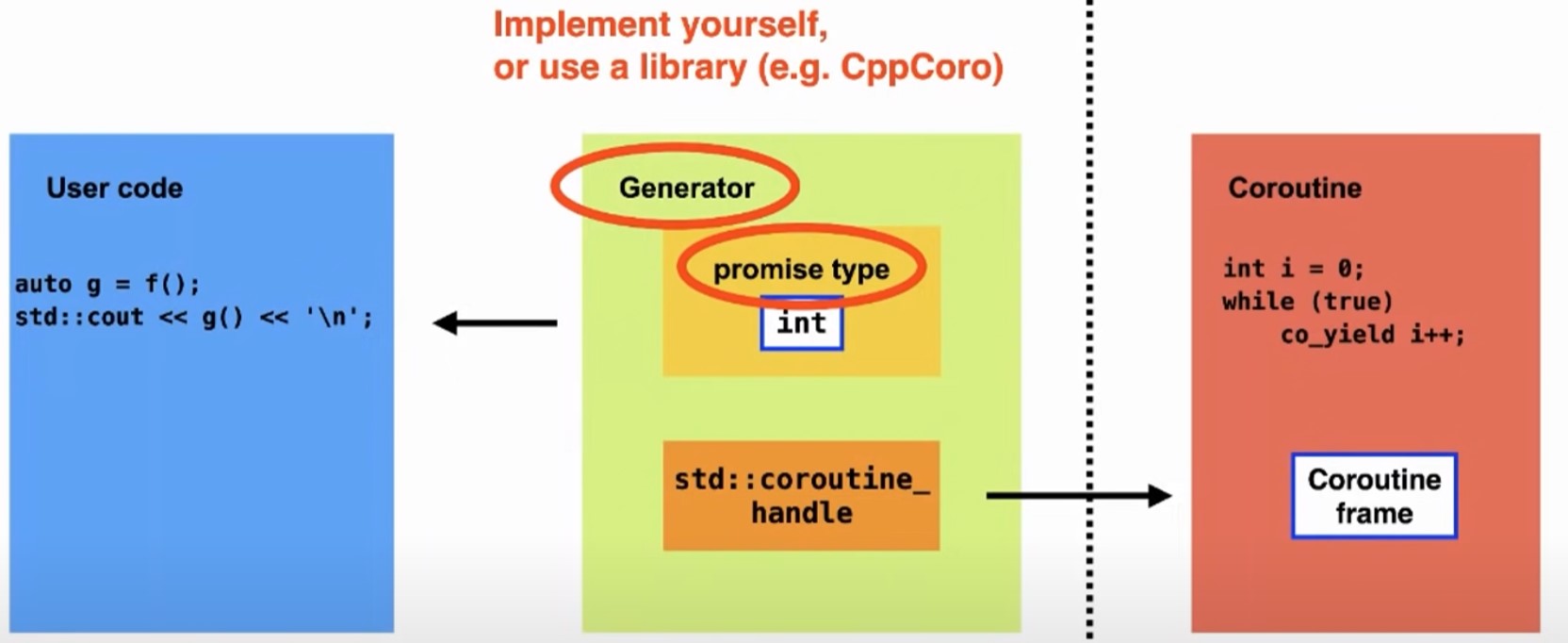
}- Generator and Coroutine API:
- Coroutines in C++ do not return a simple type (like
int) directly but instead return a generator object, which is necessary to manage and retrieve the values produced by the coroutine. - The coroutine returns a generator, which acts as the interface for retrieving the values it produces.
- This introduces an additional layer between the function call and the value retrieval, reflecting C++'s explicit handling of operations.
- Coroutines in C++ do not return a simple type (like
my_generator<int> f() {
my_generator<int> int i = 0;
while (true) co_yield i++;
}
int main() {
auto g = f();
std ::cout << g() << '\n';
std ::cout << g() << '\n';
std ::cout << g() << '\n';
}
-
Promise Type and Coroutine Handle:
- A
promise typeacts as a container for values produced by the coroutine, analogous tostd::optional. - The
coroutine handlepoints to acoroutine frame, which contains the state (local variables, control flow points) of the coroutine, allowing it to pause and resume execution.
- A
-
Coroutine Frame:
- Unlike traditional functions that have a stack-bound lifetime, a coroutine's state (or frame) can persist beyond the stack, typically requiring dynamic memory allocation.
- Coroutines manage state transitions using a state machine logic, optimized by the compiler for efficient re-entrance and execution.
-
Optimizations and Language Support:
- The coroutine's behavior and lifecycle can sometimes be optimized to avoid heap allocation, depending on its usage context and compiler capabilities.
- Efficient coroutine implementation necessitates language-level support, not just libraries, due to the complexity of their state management and execution optimizations.
-
Future Enhancements in C++23:
- C++20 does not provide a standard
generatortype; users must implement their own or use libraries like CppCore. - C++23 is expected to introduce a standard
generatortype, improving support for coroutines and simplifying their usage in standard C++.
- C++20 does not provide a standard
Don't do this by yourself
- Using established libraries such as CppCoro is strongly recommended to avoid the intricate details of coroutine implementation and to leverage pre-tested, efficient solutions.
template <typename T>
struct generator {
struct promise_type;
using handle_type = std::coroutine_handle<promise_type>;
handle_type handle;
struct promise_type {
// implementation ...
}
generator(const generator&) = delete;
generator& operator=(const generator&) = delete;
generator(generator&& other) : handle(other.handle) {
other.handle = nullptr;
};
generator(promise_type& promise)
: handle(handle_type::from_promise(promise)) {}
generator& operator=(generator&& other) {
if (this != &other) {
handle = other.handle;
other.handle = nullptr;
return *this;
}
~generator() {
if (handle) handle.destroy();
}
T operator()() {
assert(handle != nullptr);
handle.resume();
return handle.promise().current_value;
}
}
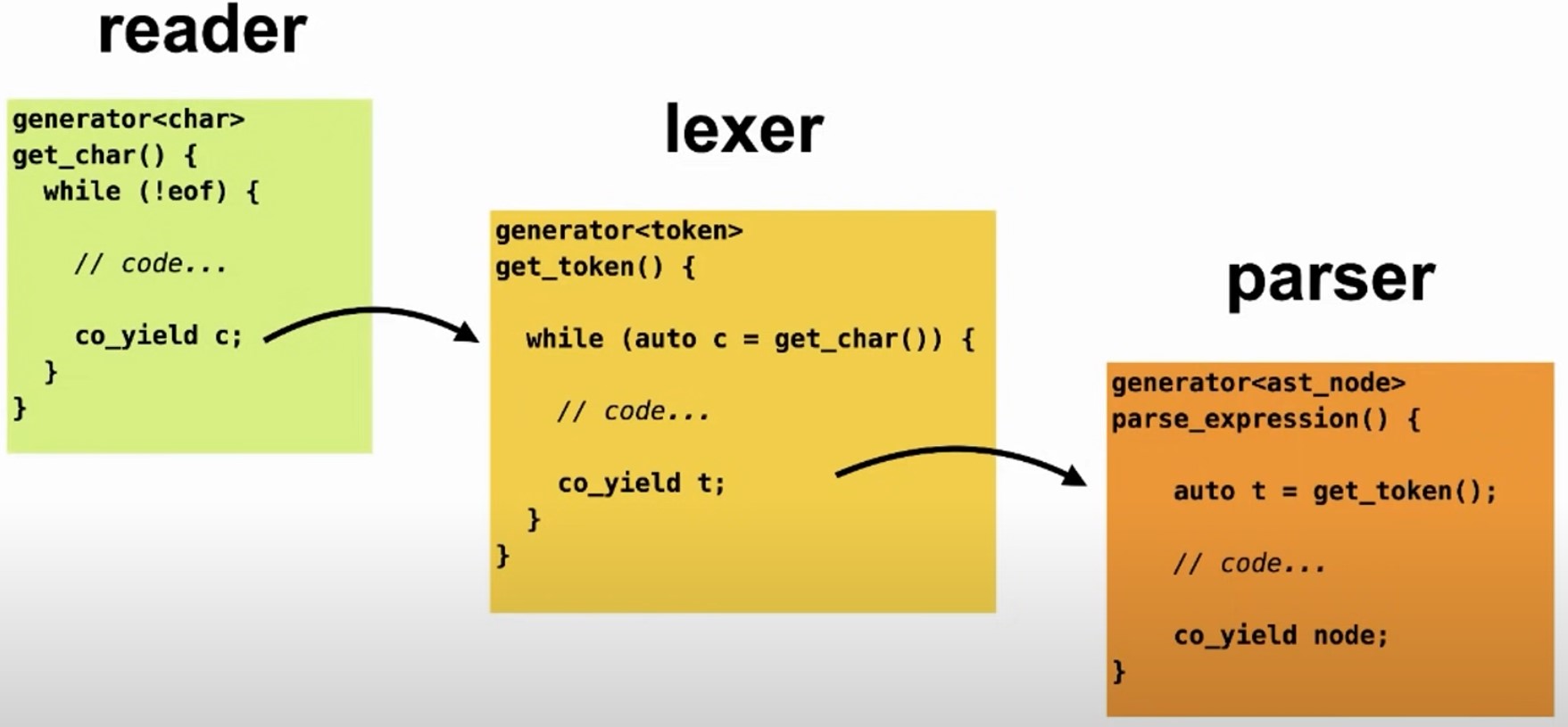
};Using coroutine to simplify lexer works
-
Sequential processing where each step completes before the next begins, often requiring storage of intermediate results and complex class structures.
-
Coroutine Approach allows for lazy and cooperative processing between different stages:
- Lexer Coroutine: Pauses after generating each token and resumes when the parser requests a new token.
- Reader Coroutine: Supplies characters to the lexer as needed, pausing and resuming based on lexer requests.
-
Benefits of Using Coroutines:
- Efficiency: Reduces memory usage by eliminating the need to store entire data streams (e.g., full file contents) before processing.
- Modularity: Each stage of processing maintains its state independently, simplifying the code structure and making it more understandable.
- Cooperative Multitasking: Coroutines work together seamlessly, each performing its task and yielding control as needed without the overhead of managing threads or complex callback structures.
-
Impact on Multithreaded Environments:
- Avoids Callback Hell: Traditional multithreaded programming often involves intricate and error-prone callback mechanisms where logic is scattered and difficult to manage.
- Simplifies Logic and Debugging: Coroutines provide a linear and clear flow of logic, even in multitasking scenarios, making the code easier to write, follow, and debug.
- Cooperative vs. Preemptive Multitasking: Coroutines allow threads to cooperate effectively, each handling its part smoothly and yielding control, as opposed to preemptive multitasking which involves forcibly switching contexts, often leading to efficiency losses and complexity.
Coroutine Functionality with co-wait
-
Role of
co-wait: Extends coroutine capabilities by allowing a coroutine to suspend its execution until another coroutine it depends on yields a value or completes. -
Compiler Recognition of Coroutines: Usage of keywords like
co-yield,co-wait, andco-returnsignals to the compiler that a function is a coroutine. These are the only syntactic markers needed to define a coroutine. -
Cooperative Interaction Between Coroutines:
- Behavior of
co-wait: When coroutinef1usesco-waiton coroutinef2,f1suspends. Whenf2later yields a value, it resumesf1, allowing it to continue from the point of suspension. - Communication via Callbacks: Essentially,
co-waitfunctions like a registration for a callback withinf2forf1. Whenf2yields, it triggers the callback, continuing the execution off1.
- Behavior of
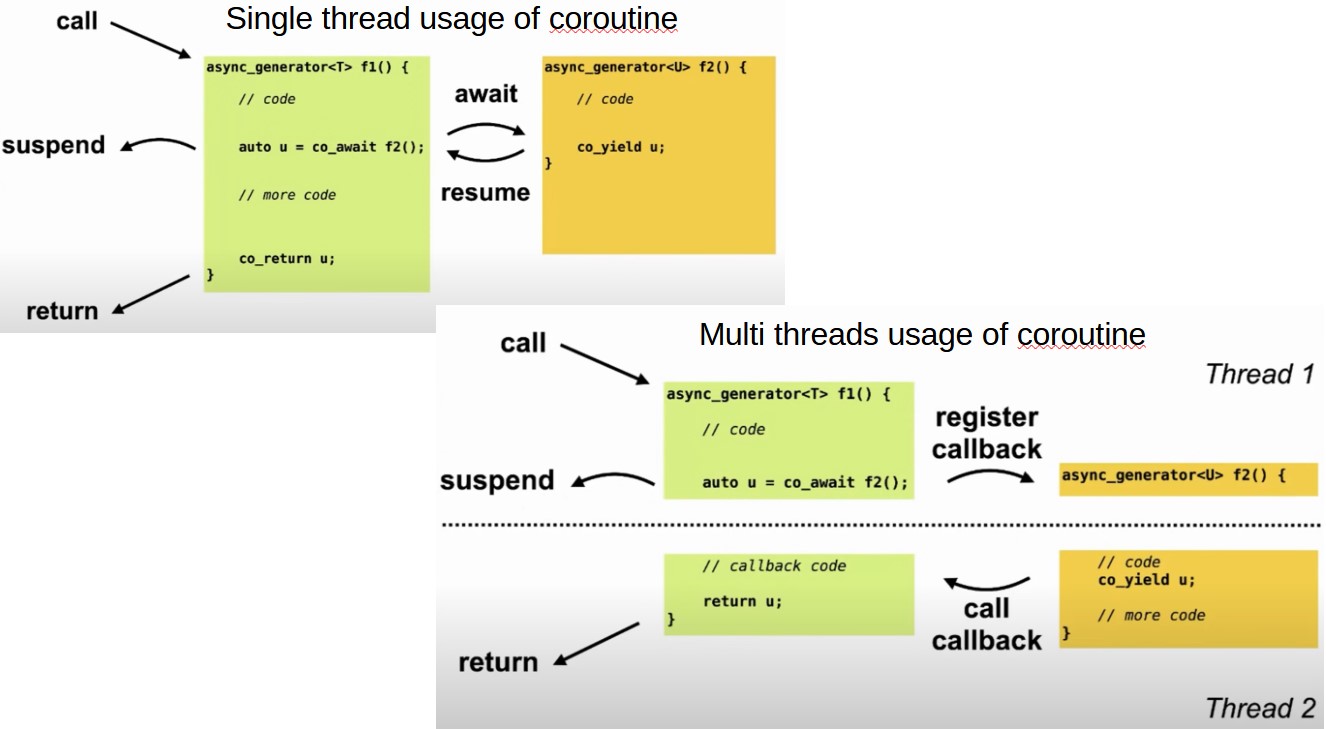
- Concurrency and Thread Safety:
- Multithreaded Considerations: The example illustrates the potential for
f1andf2to operate on different threads, enhancing the efficiency and responsiveness of the program. - Importance of Thread Safety: If coroutines operate across threads, the promise type and generator must handle synchronization to prevent race conditions, such as using mutexes or other locking mechanisms.
- Multithreaded Considerations: The example illustrates the potential for
Coroutines vs. Threads
- Independence from Threads: Coroutines are not inherently tied to threading or asynchronous programming; they are about suspending and resuming execution which can be applied in single-threaded contexts as well.
- Thread-Safe Implementation: While coroutines themselves do not manage thread contexts, the structures that support them (like generators or promise types) may need to be designed to be thread-safe to ensure correct operation in a multithreaded environment.
Concepts
// PRE C++20: SFINAE, you can put this onto the return type of the function, but
// then you don't really see the actual return type anymore, so that's not great
template <typename T>
auto is_power_of_2(T i) -> std::enable_if_t<std::is_integral_v<T>, bool> {
return i > 0 && (i & (i - 1)) == 0;
}
template <typename T>
auto is_power_of_2(T x) -> std::enable_if_t<std::is_floating_point_v<T>, bool> {
int exponent;
const T mantissa = std::frexp(x, &exponent);
return mantissa == T(0.5);
}
// -------------------------------------------------------------
// You can put SFINAE into the parameter list, but then you don't really see the
// parameter list anymore, so not ideal as well.
// You can also put this into the template argument list, because then you can
// still cleanly see the function signature. It seems to be he most readable way
// of doing SFINAE, except it doesn't work, because it turns out that in C++
// defaulted template arguments are not part of the function signature. And then
// you again have the same function signature twice, and then you again get this
// error redefinition of function template.
template <typename T, typename = std::enable_if_t<std::is_integral_v<T>>>
bool is_power_of_2(T i) {
return i > 0 && (i & (i - 1)) == 0;
}
template <typename T, typename = std::enable_if_t<std::is_floating_point_v<T>>>
bool is_power_of_2(T x) {
int exponent;
const T mantissa = std::frexp(x, &exponent);
return mantissa == T(0.5);
}
// -------------------------------------------------------------
// you can work around that, because that rule doesn't apply to non-type
// template parameters. So you can make this an int template parameter, and
// that's going to work. this is actually not good either, because int, people
// use int as a legit non-type template parameter. Someone could just put a
// value in there, and that's going to break this whole thing.
template <typename T, std::enable_if_t<std::is_integral_v<T>, int> = 0>
bool is_power_of_2(T i) {
return i > 0 && (i & (i - 1)) == 0;
}
template <typename T, std::enable_if_t<std::is_floating_point_v<T>, int> = 0>
bool is_power_of_2(T x) {
int exponent;
const T mantissa = std::frexp(x, &exponent);
return mantissa == T(0.5);
}
// what you should be doing instead is you should make it a void pointer
// non-type template parameter, and you should default it to a null pointer.
// But who's supposed to remember how to figure out how to use this correctly?
template <typename T, std::enable_if_t<std::is_integral_v<T>, void*> = nullptr>
bool is_power_of_2(T i) {
return i > 0 && (i & (i - 1)) == 0;
}
template <typename T,
std::enable_if_t<std::is_floating_point_v<T>, void*> = nullptr>
bool is_power_of_2(T x) {
int exponent;
const T mantissa = std::frexp(x, &exponent);
return mantissa == T(0.5);
}
// C++ 20, much less SFINAE hassles
template <typename T>
requires std::is_integral<T>
bool is_power_of_2(T i) { return i > 0 && (i & (i - 1)) == 0; }
template <typename T>
requires std::is_floating_point<T>
bool is_power_of_2(T x) {
int exponent;
const T mantissa = std::frexp(x, &exponent);
return mantissa == T(0.5);
}
// or
template <std::is_integral T>
bool is_power_of_2(T i) { return i > 0 && (i & (i - 1)) == 0; }
template <std::floating_point T>
bool is_power_of_2(T x) {
int exponent;
const T mantissa = std::frexp(x, &exponent);
return mantissa == T(0.5);
}More on concepts
You can combining concepts and expressions
#include <concepts>
template <typename T>
concept arithmetic = std::integral<T> || std::floating_point<T>;
template <typename T>
concept my_number = arithmetic<T> && sizeof(T) <= 8;
auto f(my_number auto x) {
// code ...
}
int main() {
auto x = f(2.0); // OK
auto y = f(2.0L); // error: no matching function for call to 'f'
// note: candidate template ignored: constraints not satisfied
// note: because 'long double' does not satisfy 'my_number'
// note: because 'sizeof(long double) <= 8' (16 <= 8)
evaluated to false
}- Design Shift: Concepts encourage a shift in how libraries are designed, focusing first on defining the necessary concepts or "contracts" that types must fulfill.
- Documentation vs. Code: Moves constraints from documentation into code, making them explicit and compiler-enforceable, reducing runtime errors and improving code reliability.
- Flexibility and Power: Concepts enable more flexible, powerful library designs and can make certain libraries feasible that would be challenging or impossible to implement without such precise type constraints.
// This concept checks that a type T can be hashed to a std::size_t, defining
// exactly what operations a type must support to be used as a key in a hashmap.
template <typename T>
concept hashable = requires(T t) {
{ std::hash<T>{}(t) } -> std::convertible_to<std::size_t>;
};
// Only types that satisfy the hashable concept can be used with this hash map,
// ensuring type safety and clear interface requirements.
template <hashable T>
class hash_map;Range
// Pre C++20 ranges, when you want to sort vector...
auto sort_by_age = [](auto& lhs, auto& rhs) { return lhs.age < rhs.age; };
std::sort(users.begin(), users.end(), sort_by_age);
// with C++20 ranges, you can do:
std::ranges::sort(users, sort_by_age);
// But how is it designed? With C++20 concepts!
template <random_access_range R, typename Comp = ranges::less,
typename Proj = identity>
requires sortable<iterator_t<R>, Comp, Proj>
constexpr safe_iterator_t<R> ranges::sort(R&& r, Comp comp = {},
Proj proj = {});
// so what is sortable ...?
template <typename I, typename R = ranges::less, class P = identity>
concept sortable =
permutable<I> && indirect_strict_weak_order<R, projected<I, P>>
// so what is permutable?
template <typename I>
concept permutable =
forward_iterator<I> &&
indirectly_movable_storable<I, I> &&
indirectly_swappable<I, I>;- Clear Constraints and Interfaces: Concepts explicitly define what functionalities a type must support to be used in a specific context, significantly cleaning up the interface and usage of templates.
- Reduced Complexity in Implementation: The use of concepts avoids the intricate template metaprogramming previously necessary with SFINAE, leading to more readable and maintainable code.
Transformative power of C++20 Ranges
const std::vector<User> users = {/* ... */};
bool underage(const User& user) { return user.age < 18; };
std::vector<User> filtered_users;
// Pre C++20
std::copy_if(users.begin(), users.end(), std::back_inserter(filtered_users),
std::not_fn(underage));
std::transform(filtered_users.begin(), filtered_users.end(),
std::ostream_iterator<int>(std::cout, "\n"),
[](const auto& user) { return user.age; });
// C++20
auto result =
users |
std::views::filter(std::not_fn(underage))
std::views::transform([](const auto& user) { return user.age; });
std::ranges::copy(result, std::ostream_iterator<int>(std::cout, "\n"));
-
Efficiency and Laziness:
- Laziness: The range operations do not perform any work until the final output is required (at the point of
std::ranges::copy). This lazy evaluation prevents unnecessary data processing and memory usage. - Functional Style: Using the pipe operator (
|) to chain operations is reminiscent of functional programming, making the code more expressive and easier to understand.
- Laziness: The range operations do not perform any work until the final output is required (at the point of
-
Avoidance of Loops and Temporaries:
- Ranges eliminate the need for explicit loops and temporary containers to hold intermediate results. The operations directly express what the programmer intends without specifying how it should be performed (declarative).
- This leads to cleaner, more maintainable code, especially in complex data processing tasks.
-
Views and Composability:
- Views: Are lightweight wrappers around data that do not own the data but provide a way to access and manipulate it through range operations.
- Composability: Views can be composed using pipes, allowing complex operations to be built up from simple ones. Each view is responsible for one aspect of data transformation or filtering, adhering to the Single Responsibility Principle.
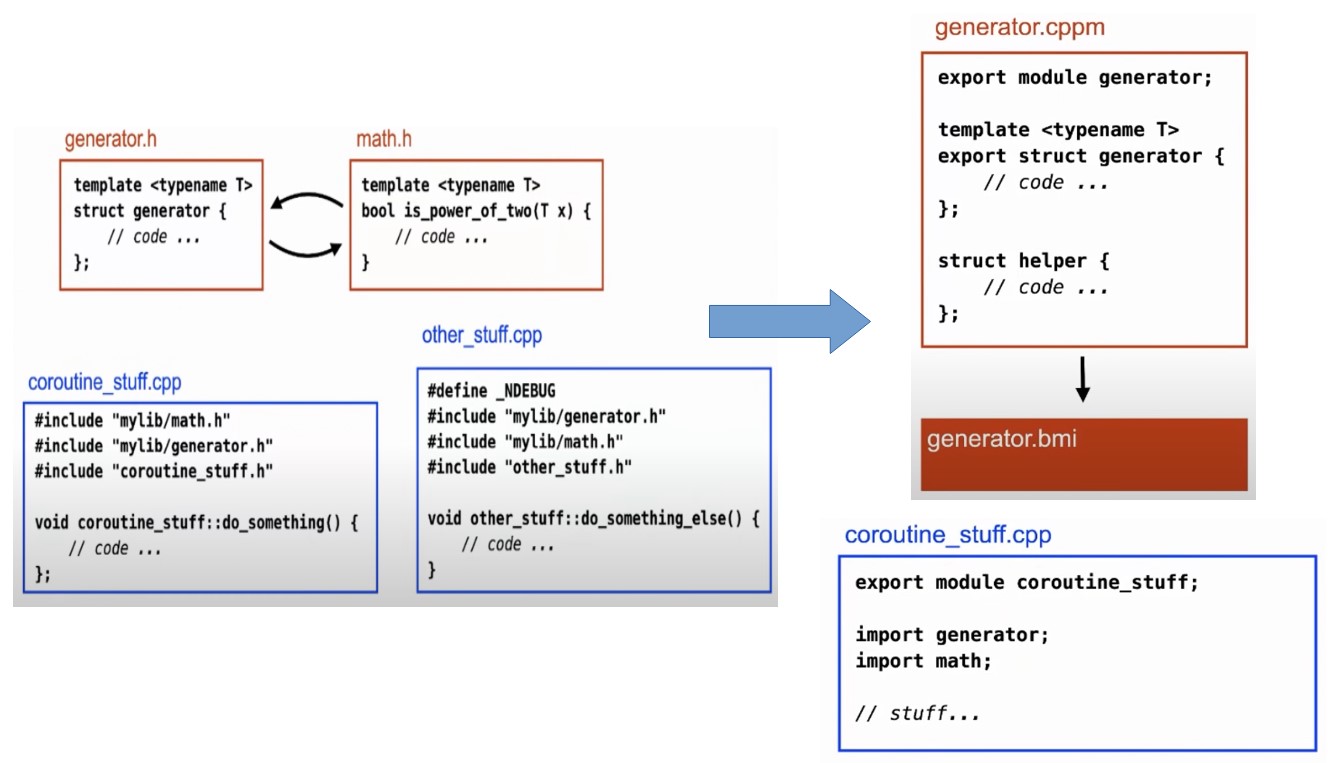
Modules
-
Issues with Traditional Header Files:
- Repeated Parsing and Compilation: Each header is processed multiple times across different translation units, leading to increased compilation times and resource usage.
- Macro Pollution: Macros defined before an include can affect the included headers, potentially altering their behavior or leading to inconsistencies.
- Lack of Encapsulation: It's difficult to hide implementation details effectively using headers alone, which can expose internal structures that should be private.
-
Introduction of Modules:
- Solves Common Header Problems: Modules address many of the intrinsic problems with header files by encapsulating code and reducing the need to include headers multiple times across different translation units.
- Isolation from Macros: Macros do not leak into or out of modules, preventing unexpected side effects on the module's internal and external environment.
- Efficiency in Compilation: Modules need to be compiled only once, and subsequent uses refer to a precompiled form, significantly speeding up the build process.
-
Module Design:
- Export and Encapsulation: Only the explicitly
exported entities in a module are accessible from outside the module, which enhances encapsulation and hides implementation details effectively. - Binary Module Interface (BMI): A module compiles into a BMI, which is a compiler-specific representation that speeds up compilation but is not intended to be shared or distributed due to its dependency on the compilation environment.
- Export and Encapsulation: Only the explicitly
Bonus change - erase
// Pre C++20
v.erase(std::remove_if(v.begin(), v.end(), [](int i) { return i % 2 == 1; }),
v.end());
// C++20 finally fix it!
std::erase(v, [](int i) { return i % 2 == 1; });- C++20 has a lot of stuff like this. It just removes a lot of these obstacles.
Conclusion
- The four new features: coroutines, concepts, ranges, and modules basically change how we think about functions, templates, algorithms, and how we compile and distribute our code respectively.
- These are all very fundamental and influential!