coroutine_patterns_problems_and_solutions
Coroutine Patterns: Problems and Solutions Using Coroutines in a Modern Codebase - Francesco Zoffoli
Understanding Tasks and Executors in Coroutine Context
Fundamentals of Tasks in Coroutines:
A task in the context of C++ coroutines, particularly when discussing libraries like Folly, is a central concept that encapsulates the coroutine's state and execution logic. Here are the essential characteristics and functionalities of a task:
-
Ownership of Coroutine State:
- The task object is responsible for maintaining all the state information necessary for the coroutine's execution. This includes local variables, suspension points, and the overall progress of the coroutine.
-
Laziness (Deferred Execution):
- Tasks are typically lazy, meaning their execution doesn't start immediately upon creation. Instead, a task begins executing when something explicitly awaits it. This deferred execution model is crucial for optimizing resource usage and improving responsiveness in applications.
-
Convertibility to Eager Execution:
- While tasks are lazy by default, they can be converted to eager tasks. An eager task starts execution as soon as it is created, contrasting with the lazy approach where execution is deferred until the task is awaited.
-
Propagation of Executors:
- Executors are entities that manage how and where tasks run (e.g., on which thread or thread pool). When a task is created on a particular executor, all tasks spawned from it (directly or indirectly awaited tasks) inherit this executor unless explicitly changed. This propagation ensures that task execution is predictable and confined to specified execution contexts.
-
Sticky Relationship with Executors:
- In Folly, tasks exhibit a "sticky" behavior to their executors. Once a task starts executing on a specific executor, it will continue to execute on this executor throughout its lifecycle, unless the task explicitly changes its executor. This model prevents unintended "executor leaks," where a task might inadvertently migrate between different executors.
Example of Task Usage:
Consider a simple coroutine function that utilizes these concepts:
#include <iostream>
#include <chrono>
#include <thread>
// Mimics a sleep function in a coroutine-friendly way
struct Sleep {
std::chrono::seconds duration;
bool await_ready() const noexcept { return duration.count() <= 0; }
void await_suspend(std::coroutine_handle<> h) {
std::this_thread::sleep_for(duration);
h.resume();
}
void await_resume() const noexcept {}
};
// Task that prints a message, sleeps, then resumes
Task<> foo() {
std::cout << "Hello, ";
co_await Sleep{std::chrono::seconds(1)}; // Sleep for 1 second
}
int main() {
auto t = foo(); // Create the task; does not start yet
std::cout << "world\n";
co_await std::move(t); // Start/resume the task
return 0;
}Output Explanation:
In this scenario, the output would be "world\nHello, ". Here's why:
- The task
foois initiated but, due to its lazy nature, doesn't start immediately. - "world\n" is printed next by the main flow.
- Finally,
foois explicitly awaited, causing it to resume and print "Hello, " after a 1-second pause.
Executor
Coroutines transform asynchronous code into a more manageable and readable format compared to traditional callback-based programming. To fully grasp their behavior and interaction with executors, let's delve into a detailed example and explanation.
Task<> foo() {
int a = 42;
a -= 10;
int bytes = co_await send(a);
if (bytes == -1) {
handle_error();
}
}In this coroutine, foo, we perform a simple calculation and then co_await on an asynchronous send operation. The co_await effectively splits the coroutine into two parts:
- Pre-await: Handles initialization and sending operation.
- Post-await: Handles the response and error checking.
How Executors Manage Coroutines
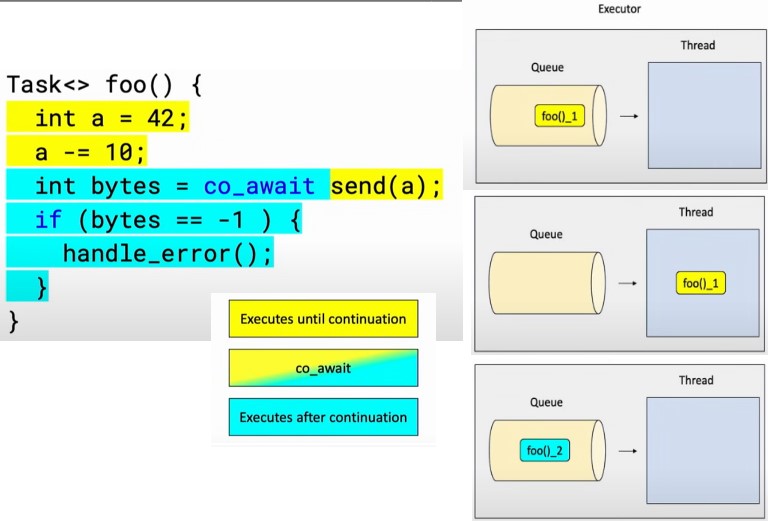
Executors are pivotal in managing how coroutines are executed. Think of an executor as a system that manages a queue of tasks (functions) to be executed on one or more threads.
Executor Responsibilities:
- Task Queue Management: Executors maintain a queue where tasks are held until a thread is available to execute them.
- Thread Management: Executors decide on which thread a task will run. This can be a single thread or a pool of threads depending on the complexity and requirements of the application.
Coroutine and Executor Workflow
-
Splitting of Coroutine:
- The compiler transforms the coroutine into a set of synchronous functions divided at suspension points (
co_await). - The first part (pre-await) runs until it reaches the
co_await, preparing the data to be sent. - The second part (post-await) is triggered after the asynchronous operation completes, handling the results.
- The compiler transforms the coroutine into a set of synchronous functions divided at suspension points (
-
Execution Flow:
- When
foois invoked, it is initially lazy and does not start immediately. - On awaiting
foo(co_await foo()), the first synchronous part is enqueued in the executor’s task queue. - A thread from the executor’s pool picks up the task and runs it until it hits the
co_await, at which point it suspends, freeing the thread to perform other work. - Upon completion of the awaited asynchronous operation (
send), the second part of the coroutine is enqueued to the executor’s task queue. - The same or a different thread may execute the continuation of the coroutine, depending on the executor's configuration and state.
- When
-
Handling of
co_await:co_awaitin coroutines not only marks the suspension points but also orchestrates the handover between the coroutine and the executor.- The
await_suspendfunction of the awaitable (sendin this case) is called with a coroutine handle, which is an identifier or pointer to the coroutine's frame (state). - This handle can then be used to resume the coroutine once the asynchronous operation is complete.
Practical Implications
- Asynchronicity Management: Coroutines simplify managing asynchronous operations by abstracting the complexity of callbacks and state machines into a more linear and readable form.
- Resource Efficiency: By suspending execution at
co_awaitand only using threads when active work is required, coroutines help in utilizing system resources more efficiently, preventing thread blockage and reducing context switching overhead.
Lifetime
This part might need to check back...
Structured Concurrency: Principles and Practices
Structured concurrency ensures that when you spawn concurrent tasks (coroutines, threads, etc.) within a certain scope, these tasks must all complete before you exit that scope. This management strategy prevents several common issues in concurrent programming such as dangling pointers, race conditions, and memory leaks.
Key Principles
-
Joining on Work: When you initiate concurrent work within a scope (like a function or a block of code), you must ensure that this work joins back—i.e., completes—before exiting the scope. This prevents the scope from terminating while still having outstanding asynchronous operations, which might continue to run in the background.
-
Local State Safety: By ensuring that all asynchronous operations complete before the scope ends, you can safely reference local variables within these operations without the risk of accessing destroyed data. For instance, if a coroutine captures local references or pointers, those references will remain valid as long as the coroutine completes before the function ends.
-
Memory Management: Structured concurrency inherently reduces the risk of memory leaks and pointer issues because all tasks must complete before the scope ends, allowing for deterministic resource management and cleanup.
Example
#include <coroutine>
#include <iostream>
struct Task {
struct promise_type {
Task get_return_object() {
return Task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_never initial_suspend() { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void return_void() {}
void unhandled_exception() { std::exit(1); }
};
std::coroutine_handle<promise_type> coro;
Task(std::coroutine_handle<promise_type> h) : coro(h) {}
~Task() {
if (coro) coro.destroy();
}
};
Task do_work() {
std::cout << "Work done\n";
co_return;
}
int main() {
auto task = do_work();
// The coroutine will complete its work and be destroyed before exiting main.
}Address Sanitizer (ASAN) and Rare Abstractions
When building abstractions that do not neatly fit into the structured concurrency model, particularly those used across a codebase (like generic libraries or utilities), additional care is needed:
-
Using ASAN: AddressSanitizer (ASAN) can be extremely useful for detecting memory issues such as leaks, out-of-bounds access, and use-after-free errors in complex asynchronous code. It's a tool that instruments your code to detect memory bugs automatically.
-
Testing Rare Abstractions: Since these abstractions are central and reused across various parts of the program, dedicating effort to rigorously test them is crucial. This ensures that any concurrency or memory safety issues are identified and resolved early in the development process.
Implicit this Capture in Member Functions
In the context of C++ coroutines, any member function that is a coroutine will implicitly capture the this pointer if it accesses any member variables or functions. This is crucial to understand for memory safety:
- Lifetime Management: You must ensure that the object to which
thispointer refers remains alive for the duration of the coroutine's execution. Failing to do so can lead to undefined behavior and crashes due to dereferencing a dangling pointer.
Here is a practical advice for managing this in coroutines:
struct MyObject {
int value = 42;
Task<int> getValue() {
co_return value;
}
};
Task<void> useObject() {
MyObject obj;
auto valTask = obj.getValue();
int val = co_await valTask; // Safe: `obj` lives as long as `valTask`.
std::cout << "Value: " << val << std::endl; // Outputs 42
}
int main() {
auto task = useObject();
while (!task.await_ready()) {
std::this_thread::yield();
}
}Scenario Explanations
#include <chrono>
#include <coroutine>
#include <iostream>
#include <thread>
using namespace std::chrono_literals;
struct Task {
struct promise_type {
int value;
Task get_return_object() {
return Task{std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_never initial_suspend() { return {}; }
std::suspend_always final_suspend() noexcept { return {}; }
void return_value(int v) { value = v; }
void unhandled_exception() { std::exit(1); }
};
std::coroutine_handle<promise_type> coro;
Task(std::coroutine_handle<promise_type> h) : coro(h) {}
~Task() {
if (coro) coro.destroy();
}
int await_resume() {
return coro.promise().value;
}
bool await_ready() const noexcept { return !coro || coro.done(); }
void await_suspend(std::coroutine_handle<>) const noexcept {}
};
void sleep_for(int ms) {
std::this_thread::sleep_for(std::chrono::milliseconds(ms));
}
struct Bar {
int data = 0;
Task<int> foo() {
sleep_for(1); // simulate some delay
co_return data;
}
};
Task<int> mul_2(Task<int> t) {
int val = co_await std::move(t);
co_return 2 * val;
}
int main() {
// Placeholder for co_await calls in explanation since `main` cannot use co_await
}Scenario 1: Correct use with a named object
Bar a;
co_await a.foo();Explanation: This is correct because the object a is named and its lifetime extends throughout the coroutine foo()'s execution. Since a persists for the duration of foo(), there's no risk of accessing a destroyed object.
Scenario 2: Correct use with task transfer
Bar a;
Task<int> t = a.foo();
co_await std::move(t);Explanation: This is also safe. Although t is moved into co_await, a remains in scope and alive until after the coroutine has completed. The move semantics do not affect the lifetime of the Bar instance a but ensure that the task t can be transferred without copying.
Scenario 3: Incorrect use with a temporary object
Task<int> t = Bar{}.foo();
co_await std::move(t);Explanation: This is unsafe. The temporary Bar{} object is destroyed immediately after its construction and the call to foo(). This destruction happens right after the full expression ends, potentially before the coroutine resumes. When co_await is executed, it might access the already destroyed Bar{} instance's members, leading to undefined behavior.
Scenario 4: Correct use with a temporary object directly in co_await
co_await Bar{}.foo();Explanation: This is safe. The temporary Bar{} object's lifetime is extended to the lifetime of the coroutine it is involved in. The full expression co_await Bar{}.foo(); includes the coroutine's suspension, effectively prolonging the temporary Bar{} instance until after the coroutine completes.
Scenario 5: Correct use with mul_2 and a named object
Bar a;
Task<int> t = mul_2(a.foo());
co_await std::move(t);Explanation: This is correct. The Bar instance a is alive throughout the coroutine mul_2(a.foo())'s execution because a is a named object whose lifetime extends beyond the coroutine's lifetime.
Scenario 6: Incorrect use with mul_2 and a temporary object
Task<int> t = mul_2(Bar{}.foo());
co_await std::move(t);Explanation: This is unsafe for the same reasons as Scenario 3. The Bar{} object is a temporary that does not survive past the creation of t. Thus, when mul_2 is eventually awaited, it may operate on a destroyed object, leading to undefined behavior.
Scenario 7: Correct use with mul_2 directly in co_await
co_await mul_2(Bar{}.foo());Explanation: This is safe, mirroring the logic
Shard knowledge of pattern
Handling Coroutines in Loops and with Lambdas
Issue with Loops
In the loop example, you correctly identified the risk of Foo objects going out of scope before the coroutine completes:
vector<Task<>> tasks;
for (int index = ...) {
Foo foo{index};
tasks.push_back(foo.bar());
co_await collectAll(tasks);
}Solution: To mitigate this, you can extend the lifetime of each Foo instance:
vector<Task<>> tasks;
vector<Foo> foos; // Store `Foo` instances to extend their lifetimes
for (int index = ...) {
foos.emplace_back(index);
tasks.push_back(foos.back().bar());
}
co_await collectAll(tasks);By maintaining a vector of Foo instances (foos), each Foo's lifetime extends to match the scope of tasks, ensuring that all tasks can complete safely without accessing destructed Foo instances.
Issue with Lambdas
Lambdas capturing local variables and used within tasks are a classic trap due to potential dangling references:
// Incorrect usage:
Task<int> d = mul_2([=]() { co_return i; }());
co_await move(d);Problems:
- The lambda captures local state by value (
i), but ifiis a local variable whose scope ends before the coroutinedcompletes, this will lead to undefined behavior. - The lambda is temporary and gets destroyed immediately after its invocation, which can lead to issues if the lambda captures by reference or if its lifetime is not properly managed.
Correct Approach:
-
Immediate Co-await:
co_await mul_2([=]() { co_return i; }());Using
co_awaitdirectly on the coroutine ensures that the lambda's lifetime is extended to the lifetime of the coroutine expression, thus preventing premature destruction. -
Storing Lambda in a Variable:
auto lam = [=]() { co_return i; }; co_await mul_2(lam());Storing the lambda in a local variable before use in a coroutine extends its lifetime appropriately, aligning it with the coroutine’s demands.
-
Using
co_invokefor Safety:Task<int> d = mul_2(co_invoke([=]() { co_return i; })); co_await move(d);co_invoke(a hypothetical utility similar tostd::invoke) ensures that the lambda is correctly managed and its lifetime is extended for the duration of the coroutine task. This function would ideally manage the coroutine’s lifecycle to ensure no temporary lambda is destructed prematurely.
Background Work and Structured Concurrency
Handling tasks that execute in the background is critical for avoiding race conditions and ensuring data integrity:
{ // Incorrect approach
Foo a;
startInBackground(a.bar());
co_await do_other_stuff(); // `a.bar()` might still be running!
}
{ // Correct approach
Foo a;
auto bgWork = startInBackground(a.bar());
co_await do_other_stuff();
co_await bgWork; // Ensures `a.bar()` completes before moving on
}Key Takeaways:
- Structured Concurrency: Always ensure that tasks started in a given scope are completed (or at least their completion is awaited) before exiting the scope. This prevents dangling references and ensures that all side effects are accounted for before the scope exits.
- Error Propagation: By awaiting background tasks before the scope exits, any exceptions thrown by these tasks are properly propagated, allowing for correct error handling.
AsyncScope
- In asynchronous code, managing exceptions and ensuring that all spawned tasks are appropriately joined or cleaned up upon errors can be complex but necessary to prevent resource leaks and undefined behaviors.
- The use of
AsyncScopeis a commendable strategy as it abstracts away some of the complexities associated with these operations.
Error Handling in Coroutines
{ // Problematic approach if do_other_stuff throws
Foo a;
auto bgWork = startInBackground(a.bar());
co_await do_other_stuff();
co_await bgWork; // Ensures `a.bar()` completes before moving on
}- The issue arises when
do_other_stuff()throws an exception. In traditional C++, resources need to be explicitly managed and cleaned up in acatchblock, but as you noted,co_awaitis not allowed withincatchblocks. This is where theAsyncScopeand structured bindings can be beneficial.
Solution Using AsyncScope and Exception Handling
struct AsyncScope {
vector<std::coroutine_handle<>> tasks;
void schedule(std::coroutine_handle<> task) {
tasks.push_back(task);
}
Task<> join() {
for (auto& task : tasks) {
co_await task;
}
}
};
{ // Improved approach with AsyncScope
Foo a;
AsyncScope asyncScope;
asyncScope.schedule(startInBackground(a.bar()));
try {
co_await do_other_stuff();
} catch (...) {
// Handle exceptions or cleanup
}
co_await asyncScope.join(); // Ensures all background tasks complete
}- In this setup,
AsyncScopecollects all tasks, andjoin()is used toco_awaiton all tasks, ensuring they complete before the scope exits, regardless of whether an exception was thrown.
Utilizing co_awaitTry for Safer Error Handling
- The
co_awaitTryfunction can simplify handling by wrapping the coroutine execution in a manner that captures exceptions into a manageable form, similar tostd::expected:
Task<std::expected<int, std::exception_ptr>> co_awaitTry(Task<int> task) {
try {
co_return std::expected<int, std::exception_ptr>(co_await task);
} catch (...) {
co_return std::make_unexpected(current_exception());
}
}
{ // Using co_awaitTry to handle exceptions gracefully
Foo a;
AsyncScope asyncScope;
asyncScope.schedule(startInBackground(a.bar()));
auto result = co_await co_awaitTry(do_other_stuff());
if (result.has_value()) {
println("Success: {}", result.value());
} else {
try {
std::rethrow_exception(result.error());
} catch (const std::exception& e) {
println("Error: {}", e.what());
}
co_await asyncScope.join(); // Make sure to join even if there's an error
}
}Key Takeaways
-
Exception Handling in Coroutines: Using tools like
AsyncScopecan simplify managing multiple asynchronous tasks, especially when paired with error handling patterns that capture and manage exceptions effectively. -
co_awaitTryPattern: Wrapping coroutines in aco_awaitTryfunction can transform them into tasks that either succeed and return a value or capture an exception, allowing structured and safe error handling within asynchronous coroutine workflows.
By incorporating these patterns, C++ developers can write robust, clean, and maintainable asynchronous code using coroutines, significantly reducing the risks associated with dangling references, unjoined tasks, and unhandled exceptions.
Foo a;
AsyncScope s;
for (int index = ...) {
co_await s.schedule(a.bar(index));
co_await do_other_stuff();
co_await s.join();
}RAII
Coroutines introduce complexities that challenge traditional RAII patterns, particularly when asynchronous operations are involved.
The Problem with Async Destructors
Currently, C++ does not support asynchronous destructors, which complicates the cleanup of resources managed by coroutines. This limitation requires developers to explicitly manage the cleanup process, which can lead to error-prone code and potential resource leaks if not handled carefully.
Implementing Cleanup Patterns
Given these challenges, let’s dissect the proposed cleanup pattern and explore its implications and potential pitfalls:
- Async Cleanup Pattern for Classes
class Foo {
Bar m1;
AsyncScope as;
Task<> cleanup() {
co_await collectAll(as.join(), m1.cleanup());
}
};Usage Scenario:
- Classes: For classes managing async operations, define an
async cleanup()method to ensure all asynchronous tasks are completed before the object is fully cleaned up. - Inheritance: If a class is extended, the derived class should also responsibly call
cleanup()to ensure all inherited async tasks are completed.
This pattern is necessary because destructors are synchronous and cannot contain co_await statements, which are needed to properly synchronize and complete async tasks.
Example Usage:
Foo myObject;
auto cleanupTask = myObject.cleanup();
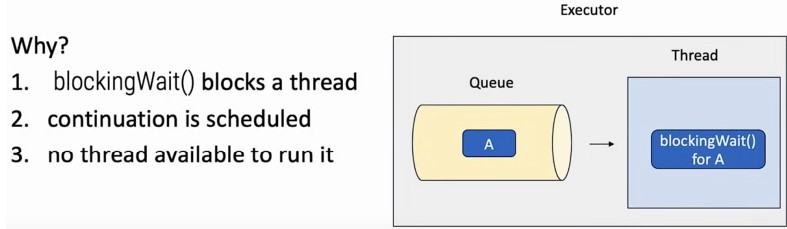
co_await cleanupTask;- Issues with Blocking Waits in Destructors
Using blocking waits inside destructors to handle async cleanup can lead to deadlocks, especially if the destructor is called on a thread that is part of the executor's thread pool:
~Foo() {
blockingWait(cleanup()); // Risky: Can cause deadlocks!
}Problem Explanation:
struct Foo {
Task<> do_work() { co_await as.schedule(sleep(1s)); }
Task<> cleanup() { co_await as.joinAsync(); }
~Foo() { blockingWait(cleanup()); }
AsyncScope as;
};
In the given example:
-
do_work()is a coroutine that schedules some work asynchronously usingas.schedule(). -
cleanup()is a coroutine that waits asynchronously for all scheduled tasks to complete usingas.joinAsync(). -
In the destructor
~Foo(),blockingWait(cleanup())is called, which synchronously waits forcleanup()to complete. -
Deadlock Scenario: The
blockingWait()function likely runs a loop that waits for the coroutine to set some completion state. However, if this coroutine (cleanup()) schedules its continuations (further tasks) on the same executor that is supposed to runblockingWait(), and if this executor is single-threaded or has all its threads busy-waiting, then those continuations cannot proceed because the thread is stuck waiting for them to complete. This leads to a deadlock: the executor waits for tasks to complete, which in turn are waiting for a chance to execute on the executor.
Synchronization
Synchronization Challenges in Coroutines
Coroutines introduce an asynchronous model that simplifies handling asynchronous operations but complicates synchronization, especially in multi-threaded environments. The need for synchronization depends critically on the access patterns and the execution environment of the coroutine.
Single-Threaded vs. Multi-Threaded Executors
Single-Threaded Executor:
- Scenario: The coroutine operates in a single-threaded context, typically using a single-thread executor.
- Synchronization Need: Minimal to none, as the single-thread model inherently serializes operations, preventing concurrent access to shared variables.
int a = 10;
co_await reschedule_on_current_executor; // Single-threaded context
do_stuff(a); // Safe without explicit syncMulti-Threaded Executor:
- Scenario: The coroutine runs in a multi-threaded context where tasks might execute concurrently on multiple threads.
- Synchronization Need: Essential, to protect shared resources and prevent race conditions.
int a = 10;
co_await collectAll(increaseBy(a, 1), increaseBy(a, 2)); // Parallel executionIn the multi-threaded scenario, the coroutine's shared variables (a in this case) need protection (e.g., using mutexes or atomic operations) to ensure thread safety.
Synchronization Techniques
-
Atomic Variables:
- Use atomic types for simple shared variables to ensure safe concurrent modifications without the overhead of mutexes.
- Suitable for simple data types and counters.
-
Mutexes and Locks:
- Regular Mutexes: Effective for protecting complex data structures or code blocks but should not span over suspension points to avoid deadlocks.
- Coroutine-Supporting Mutexes: These are designed to be safely used across coroutine suspension points, such as those provided by libraries like Folly (
folly::coro::Mutex).
folly::coro::Mutex mutex;
{
auto lock = co_await mutex.scoped_lock_async();
shared_resource.modify();
}- Folly's Synchronized Wrapper:
- A utility that provides synchronized access to a resource, ensuring that the resource is locked during access and automatically unlocked afterward.
- The lock is held only within the scope of the provided lambda, preventing it from spanning across coroutine suspension points inadvertently.
synchronized.withWLock([&](auto&) {
modify_resource(); // Executed within a lock
// co_await not allowed here, prevents suspension while locked
});And for the coroutine version, they work. They work very well, and the nice thing is they support RAII. And the reason is that unlocking the mutex is a synchronous operation, and this can be done in the destructor.
When you use coroutine locks, you might still need to access the protected state in the destructor of the class. And you should be protecting it with the lock, but the destructor cannot co-await a coroutine, as we said before.
Here, you can use try lock. Try lock immediately returns control to the caller if the lock, and telling whether they acquired the lock or not. But because you are in the destructor, nothing else can be holding the lock. So you're guaranteed the try lock is gonna succeed, and you're gonna acquire the lock. And this is the way in which you can access shared state, which is protected by a coroutine lock in the destructor. So you can use coroutine mutexes, including guards, and you can use try lock in the destructor to access state protected by a coroutine mutex.