concurrency_in_cpp_part2
Concurrency in C++: A Programmer’s Overview (part 2 of 2) - Fedor Pikus
What is an atomic operation?
- Atomic operation is an operation that is guaranteed to execute as a single transaction. E.g. Other threads will see the state of the system before the operation started or after it finished, but cannot see any intermediate state.
- At the low level, atomic operations are special hardware instructions (hardware guarantees atomicity)
- NOTE: This is a general concept, not limited to hardware instructions (example: database transactions)
int x = 0;
-----------------------
thread 1 | thread 2
++x | ++x
-----------------------
x = ?- Increment is a "read-modify-write" operations: read x from memory, add 1 to x, write new x to memory.
- Normally Read-modify-write increment is non-atomic, so there could be a data race (which will resolve to undefined behavior!)
int x = 0;
------------------------------------------
thread 1 | thread 2
int tmp = x; //0 | int tmp = x; //0
++tmp; // 1 | ++tmp; // 1
x = tmp; // 1 | x = tmp; // 1
------------------------------------------
x = 1 (!!!)More insidious atomic operation example
- On x86, in practice, for built-in types (int, long, <= 64bytes), reads and writes do not have to be atomic (though theoretically it's UB)
- E.g. when you write something into an int, and read it from other thread. The reader thread should also not see the half-result of the write. (But if you are doing, say, int 128 bytes, you don't have this guarantee)
What's really going on for atomic
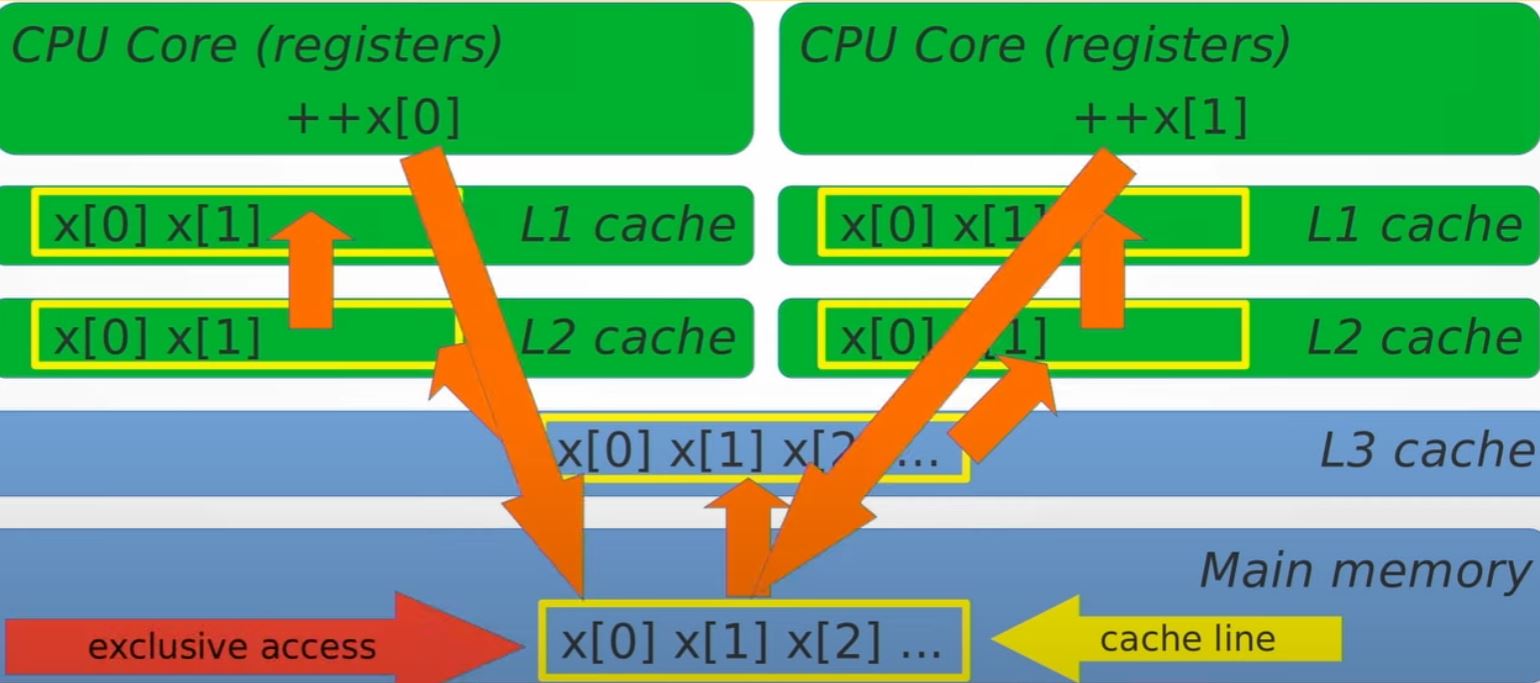
Say we have 3 threads working on 3 cores, and all accessing x. The mental model should be like:
CPU core 1 | CPU core 2 | CPU core 3 |
L1 cache | L1 cache | L1 cache |
L2 cache | L2 cache | L2 cache |
-----------------------------------------
L3 cache
-----------------------------------------
Main memory
------------------------------------------ Variable x is in the main memory, when we are going to do ++x, x is being copied into L3 cache -> L2 cache -> L1 cache, then being ++'ed by the CPU.
- All the L2 cache/L1 cache of each core/thread will all have the copy.
- What atomic do is that, if core 1 is ++'ing x, it will make sure the value is flush back to main memory, and for thread 2/core 2, thread 3/core 3, they will have to read the x again all the way from L3 cache -> L2 cache -> L1 cache
What C++ types can be made atomic?
- Any trivially copyable and copyable/movable type can be made atomic (Anything else will not compile)
What is trivially copyable?
- Continuous chunk of memory
- Copying the object means copying all bits (
memcpy) - No virtual functions,
noexceptconstructor
So:
std::atomic<int> i; // OK
std::atomic<double> x; // OK
struct S { long x; long y; };
std::atomic<S> s; // ALSO OKWhat operations can be done on these types and are all operations on atomic types atomic?
There are actually 4 group of operations
- Assignment (read and write) - always supported regardless of
T - Special atomic operations which are exclusively to atomic
- Operations depend on the type
T - Operation that just won't be supported by atomic
Think about below ...
- One can't even be compiled
- Two of these are not the same as the others
std::atomic<int> x{0};
++x;
x++;
x += 1;
x |= 2;
x *= 2;
int y = x * 2;
x = y + 1;
x = x + 1;
x = x * 2;- All operations on the atomic variable
xare atomic below (unless it's the case that it's not supported)
std::atomic<int> x{0};
++x; // Atomic pre-increment
x++; // Atomic post-increment
x += 1; // Atomic increment
x |= 2; // Atomic bit set
x *= 2; // <--- no atomic multiplication at all (won't compile)
int y = x * 2; // atomic read of x
x = y + 1; // atomic write of x
x = x + 1; // atomic read followed by atomic write, not single atomic
x = x * 2; // atomic read followed by atomic write, not single atomicstd::atomic<T> and overloaded operators
std::atomic<T>provides operator overloads only for atomic operations (incorrect code like*=-does not compile as expect)- Unfortunately, any expression with atomic variables will not be computed atomically (easy to make mistakes - like
x = x + 1andx = x * 2;--> they are not atomic likex += 1andx *= 2doesn't even compile. But they can be compiled)
:brain::rotating_light: Don't use overloaded operators on atomic!
++x;is the same asx += 1;is the same asx = x + 1;- unless x is atomic
What operations can be done on std::atomic<T> for other types?
- Assignment and copy (read and write) for all types (Built-in and user-defined)
- Increment and decrement for raw pointers
- Addition, subtraction, and bitwise logic operations for integers
- (
++,+=,-,-=,|=,&=,^=)
- (
std::atomic<bool>is valid atomic on single byte, no special operationsstd::atomic<double>is valid, but it has no special operations- No atomic increment for floating-point numbers until C++20
- (Since C++20) Atomic floating-point math is supported, but with caveat that result could differ from non-atomic
- Atomic wait and notify (C++20)
What "other operations" can be done on std::atomic<T>?
- Use explicit read and writes:
std::atomic<T> x;
T y = x.load(); // Same as T y = x;
x.store(y); // same as x = y;- Atomic exchange, unconditional
T z = x.exchange(y); // Atomically do z = x; x = y;- Conditional exchange: compare-and-swap (The key to most lock-free algorithms)
// y is old value you assume, z is what you want to become
// if you ignore y, it's a unconditional exchange, but with y, there is condition
bool success = x.compare_exchange_strong(y, z); // T& y
// If x == y, make x = z and return true
// otherwise set y = x and return false
//
// e.g. exchange only happen if your guess of old value (y) is the same as the
// actually old value (x) while performing the operation.
//
// Note that y is a reference. If you guess wrong, then y is set to the actual
// current value of xWhat is so special about CAS?
- Compare-and-swap (CAS) is used in most lock-free algorithms
- Example: atomic increment with CAS
std::atomic<int> x{0};
int oldVal = x;
while (!x.compare_exchange_strong(oldVal, oldVal + 1)) {}
// or you can simply
// x += 1;
// but it's because atomic support the += 1 operation.For int, we have atomic increment, but CAS can be used to increment doubles, multiply integers and many more.
while (!x.compare_exchange_strong(oldVal, oldVal * 2)) {}What other operations can be done on std::atomic<int>?
std::atomic<int> x;
x.fetch_add(y); // same as x += y;
int z = x.fetch_add(y); // same as z = (x += y) - y;- Also
fetch_sub(),fetch_and(),fetch_or(),fetch_xor()- Same as
-=,&=,|=,^=
- Same as
- More verbose but less error-prone than operators and expressions
- Including
load()andstore()instead ofoperator=()
- Including
:rotating_light: better avoid std::atomic overloaded operations
std::atomic<T>provides operator overloads only for atomic operations (incorrect code does not compile)- Any expression with atomic variables will not be computed atomically (easy to make mistakes)
- Member functions make atomic operations explicit
- Compilers understand you either way and do exactly what you asked (But not necessarily what you wanted)
- Programmers tend to see what they thought you meant, not what you really meant (for example,
x = x + 1isn't atomic increment, butx += 1is! So just usex.fetch_add(1)for safety!)
Question, how fast are atomic operations?
To measure, few things to note:
- Caution: measurement results will be hardware and compiler specific and should not be over-generalized!
- Caution: comparing atomic and non-atomic operations may be instructsive for understanding of what the hardware does, but it rarely directly useful (Comparing atomic operation with a thread-safe alternative is valid and useful)
- Experiment below, the higher the better (e.g. # operations per second).
- Check out code
- Note that Fidor uses
-mavx2in the talk for compiling
Atomic v.s. non-atomic
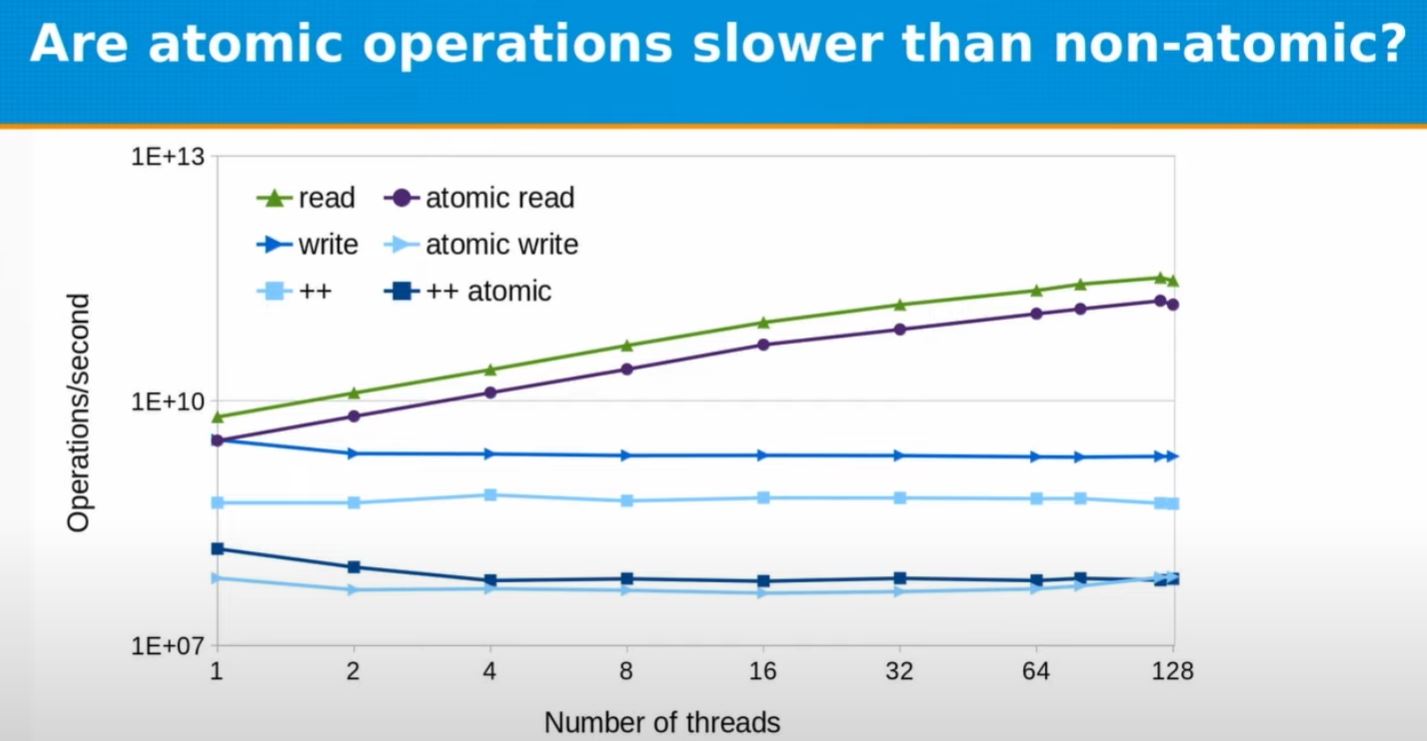
- read/atomic read are scaled with thread #
- write/atomic write aren't scaled with thread # (as at hardware level, there will be constraint)
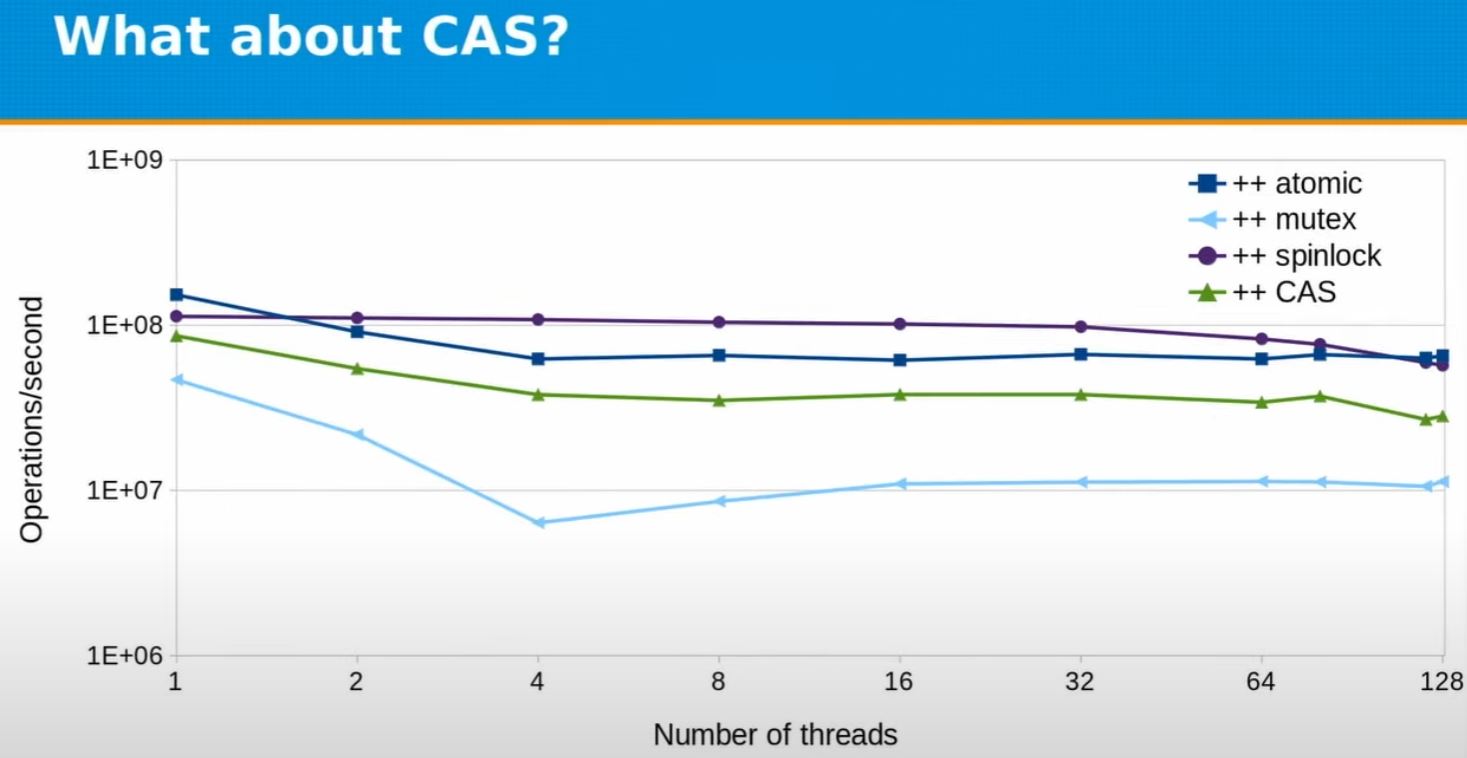
Atomic v.s. locks v.s. CAS
- std::mutex could be slow, but checkout Fedor's spinlock implementation
- Still, it's just in this context, spinlock is fast.
std::mutexmight be okay in other context.
Is atomic the same as lock-free?
:bulb: The big secret is, it's always atomic, but it's not always lock-free. E.g. it's not always done by atomic hardware instructions. Note that it will still be transactional, because of using lock.
- Throw below into godbolt.org
| Code | gcc |
|
|
long x; // std::atomic<long> is lock-free
struct A { long x; }; // // std::atomic<A> is lock-free
struct B { long x; long y; }; // nope
struct C { long x; int y; }; // nope
struct D { int x; int y; int z; }; // nope
struct E { long x; long y; long z; }; // nope- Note that
std::atomic<long>is lock-free in practice, but not required by standard - Generally you can examine with
std::atomic<T>::is_lock_free()orconstexpr std::atomic<T>::is_always_lock_free - Only
std::atomic_flagis guaranteed to be lock-free. - Compilers generate appropriate exclusion code for non-lock-free atomics.
- (Often hidden behind library calls (
libatomic)), and probably with certain spinlock + compare and swap mechanics.
- (Often hidden behind library calls (
Do atomic operations wait on each other?
- Yes, when cacheline is shared, check out code
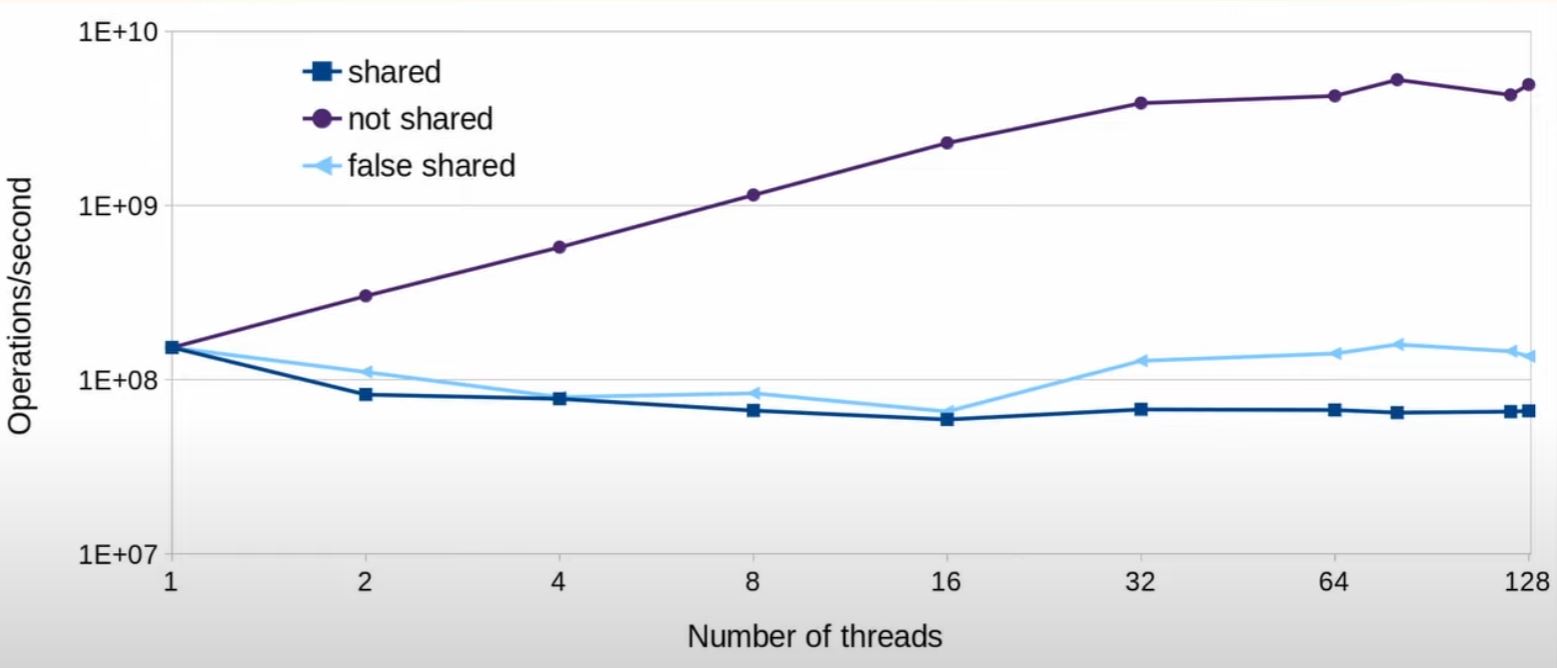
What's really going on?
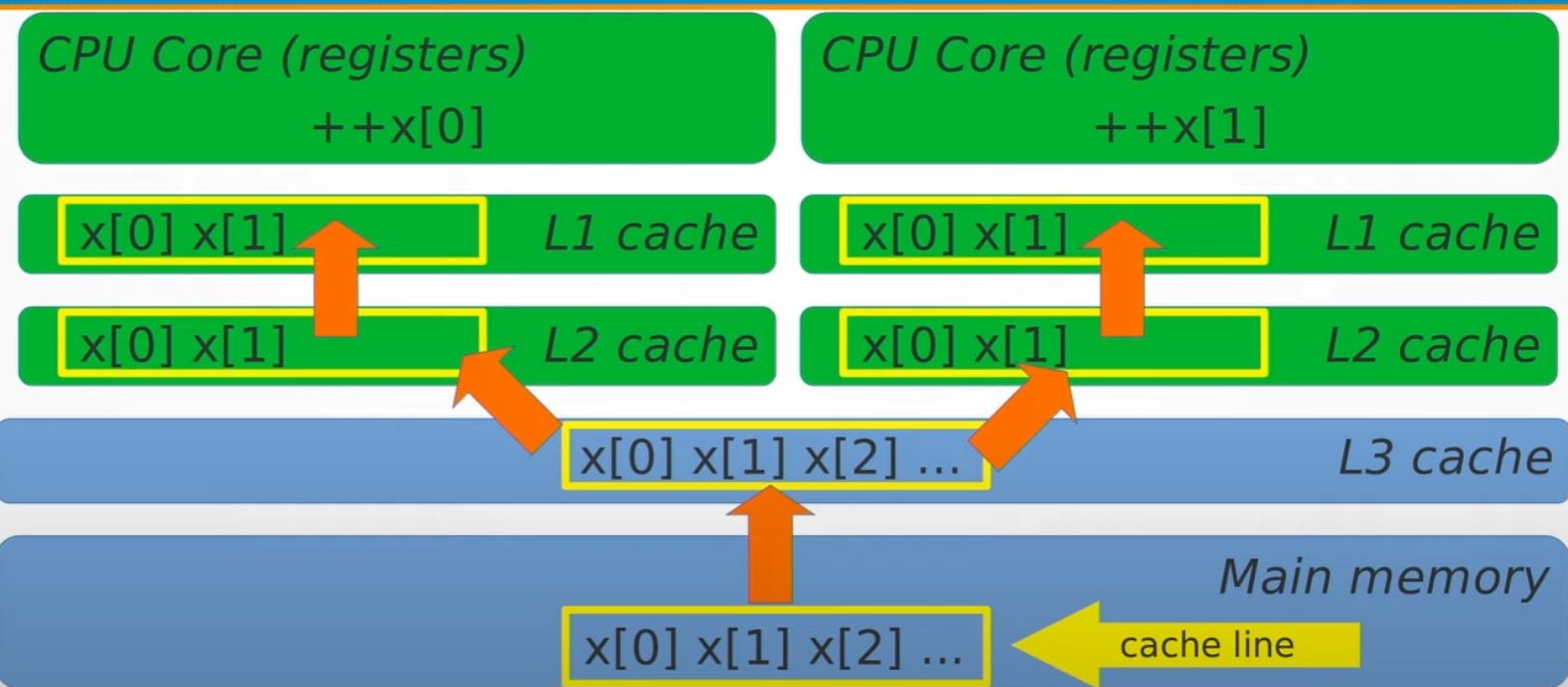 |
 |
- Cacheline is 64 bytes on x86 machine
- If you want to acquire hardware level cache, on the cache, it must lock 64 bytes at a time. And if your thread access it, it's the only one they can access the 64 bytes, even though the thread might only want to access 4 bytes out of them.
- Atomic operations do wait on each other.
- In particular, write operations do
- Read-only operations can scale near-perfectly
- Atomic operations have to wait for cacheline access
- Price of data sharing without races
- Accessing different locations in the same cacheline still incurs run-time penalty (false sharing)
- Avoid false sharing by aligning per-thread data to separate cachelines.
- On NUMA machines, maybe even on separate pages.
The C++17 cacheline size
// (C++17 feature to find L1 cache size)
// https://en.cppreference.com/w/cpp/thread/hardware_destructive_interference_size
#ifdef __cpp_lib_hardware_interference_size
using std::hardware_constructive_interference_size;
using std::hardware_destructive_interference_size;
#else
// 64 bytes on x86-64 │ L1_CACHE_BYTES │ L1_CACHE_SHIFT │ __cacheline_aligned │
// ...
constexpr std::size_t hardware_constructive_interference_size = 64;
constexpr std::size_t hardware_destructive_interference_size = 64;
#endif- What we are interested is
hardware_destructive_interference_size, the distance implies, if you are closer than this, you will have "destructive interference", e.g. one variable could lock the other one. - On the other hand,
hardware_constructive_interference_size(seems to me just the same thing with different angle.) Say variable is aligned on position 0. Then, if another variable B is within thehardware_constructive_interference_sizebytes, then we don't need to load from main memory as we've loaded the whole cacheline while accessing A. So it's "constructive".
Strong and weak compare-and-swap
- C++ provides 2 versions of CAS - weak and strong
x.compare_exchange_strong(old_x, new_x);means:
if (x == old_x) {
x = new_x;
return true;
} else {
old_x = x;
return false;
}x.compare_exchange_weak(old_x, new_x);means same thing, but can "spuriously fail" and return false even ifx == old_x.
But why would it?
- CAS, conceptually in Pseudo-code. is like below:
- (Noted that all the "lock" in Psedudo code are some cacheline wise hardware lock)
bool compare_exchange_strong(T& old_v, T new_v) {
Lock l; // say, the hardware cacheline lock
T tmp = value; // read current value of atomic
if (tmp != old_v) { // guess wrong
old_v = tmp;
return false;
}
// guess right
value = new_v;
return true;
}
bool compare_exchange_weak(T& old_v, T new_v) {
T tmp = value; // read current value of atomic without lock
if (tmp != old_v) { // guess wrong
old_v = tmp;
return false;
}
//-----------------------------------------
Lock l; // say, the hardware cacheline lock
tmp = value; // read again because value could have changed
if (tmp != old_v) { // validate again and guess wrong
old_v = tmp;
return false;
}
// guess right
value = new_v;
return true;
}- or, for the
compare_exchange_weak, if exclusive access is hard to get, it could have been a timed out version. (Hardware do have ability to timeout on lock)
bool compare_exchange_weak(T& old_v, T new_v) {
T tmp = value; // read current value of atomic without lock
if (tmp != old_v) { // guess wrong
old_v = tmp;
return false;
}
//-----------------------------------------
TimedLock l; // timed out lock!
if (!l.locked()) {
return false;
}
tmp = value; // read again because value could have changed
if (tmp != old_v) { // validate again and guess wrong
old_v = tmp;
return false;
}
// guess right
value = new_v;
return true;
}Why would we want to do the weak version? Isn't it the case that it only speed up if we always guess wrong?
- It's not good for the main thread that is trying to do the CAS - as if you guess wrongly, you are basically keep retrying.
- The reason that we do this is because on this platform, it can time out on lock. It can be shown that overall this gives faster throughput overall as it allows some other thread to do their work faster.
- The reason is likely because how expensive it is to transfer the exclusive ownership from one CPU to another.
- In timing out, it basically says "I'm on the remote CPU B" versus whoever holding the lock on CPU A.
- I'm going to give up and let someone else to try. And maybe that "someone else" is on the same CPU A as well.
- Hence they get the lock faster because letting the lock to transfer to the remote CPU B is much more expensive.
- And then when I (on the remote CPU B) get the lock (compare passed), it should mean that all the other guys working on CPU A have gave up and transfer the lock to CPU B.
- So overall, it's always worse for the one working on CPU B and keep retrying. But it's better in an aggregated way for everybody in case of strong contention.
- But remember, you have to "opt-in"/volunteer to do this using the
compare_exchange_weakcall. If you usecompare_exchange_strong, the hardware will just trying to get the lock even if the lock is currently holding by other CPU. And for the one usingcompare_exchange_weak, you are basically accepting the fact that your thread might run slower, and overall, somebody somewhere else is running faster to make up of it.
Atomic wait and notify (C++20)
// std::atomic<T> x;
// thread 1
x.wait(current_x); // block till someone notify
// equals to ...
// while (x == current_x) sleep();// thread 2
x.notify_all(); // interrupt sleep- Not pure atomic,
waitused a system callfutex, so it's not done through hardware.
Atomic variables are rarely used by themselves
// atomic queue
int q[N];
std::atomic<size_t> front;
void push(int x) {
size_t my_slot = front.fetch_add(1);
q[my_slot] = x; // my_slot is exclusive, no other thread could have seen the
// same value because of the atomic
}- Atomic variable is an index to (non-atomic) memory
- The question is, is above enough? No, it won't.
q[N]are just plain ints, there is no guaranteed that the change we make in one thread would be visible to other thread, unless it flushes to main memory. - Same thing happens to CAS, consider:
struct node { int value; node* next; };
std::atomic<node*> head;
void push_front(int x) {
node* new_node = new node;
new_node->value = x;
node* old_head = head;
// create a new_node, and keep pointing its next to old_head
// as long as old_head is still the old value we thought. And
// when this happens, we exchange head to new_node
do { new_node->next = old_head; }
while (!head.compare_exchange_strong(old_head, new_node));
}- The atomic variable is a pointer to (non-atomic) memory
Atomic variables as gateways to memory access (generalized pointers)
"Publishing protocol"
- I have a memory location. I want to publish a new piece of data on the location in a concurrent system to everybody.
- First, we prepare the data, but we don't publish the data yet. How?
- I use a
my unique ppointer to point to the new data first. But theatomic phasn't. So no one else can accessmy unique pat the moment.

- When I'm done preparing the data, I atomically repoint the pointer

- Atomics are used to get exclusive access to memory or to reveal memory to other threads.
- But most memory is not atomic. What guarantees that other threads see this memory in the desired state?
- For acquiring exclusive access: data maybe prepared by other threads, must be completed.
- For releasing into shared access: data is prepared by the owner thread, so it must become visible to everyone.
- So the rest of memory is not atomic, only the memory is atomic.
The problem comes - what if one thread change something in cache 1, the other thread also change something in cache 2, both of them hasn't been flushed into main memory?
- So atomic is not enough...
Memory barriers (a.k.a memory ordering): the "other side/the second part" of atomics
-
I can't chose to associated a memory barrier to an atomic operation, and memory barriers are things to guarantee visibility of all other memory that I have updated (not just the atomic operation)
-
Memory barriers control how changes to memory made by one CPU become visible to other CPUs
-
Visibility of non-atomic changes is not guaranteed
node* new_node = new node(...args...);
head.store(new_node);-
All threads see that list head changed. But what do they see as node data?
-
Synchronization of data access is not possible if we cannot control the order of memory access.
-
This is global control, across all CPUs.
-
Such control is provided by memory barriers, which are implemented by the hardware
-
Memory barriers are invoked through processor-specific instructions (or modifiers on other instruction)
- Barriers are often "attributes" on read/write operations, ensuring the specified order of reads and writes

Acquire barrier
-
Acquire barrier guarantees that all memory operations scheduled after the barrier in the program order become visible after the barrier.
- "All operations" not "all reads" or "all writes" but both read and writes
- "All operations" not just operations on the same variable that the barrier was on
-
Reads and writes cannot be reordered from after to before the barrier
- Only for the thread that issued the barrier

Release barrier
- Release barrier guarantees that all memory operations scheduled before the barrier in the program order become visible before the barrier.
- Reads and writes cannot be reordered from before to after the the barrier
- Only for the thread that issued the barrier

Acquire-release protocol (publishing protocol)
- Acquire and release barriers are often used together
- Thread 1 writes atomic variable x with release barrier
- Thread 2 reads atomic variable x with acquire barrier
- All memory writes that happen in thread 1 before the barrier (in program order) become visible in thread 2 after the barrier
- Thread 1 prepares data (does some writes) then releases (publishes) it by updating atomic variable x
- Thread 2 acquires atomic variable x and the data is guaranteed to be visible

Barrier and lock
Acquire and release barriers are used in locks
Lock L; // std::atomic<int> l(0);
L.lock(); // while (l.exchange(1, std::memory_order_acquire));
++x; // ++x;
L.unlock(); // l.store(0, std::memory_order_release);- You have exchange to ensure when
whilebreaks, you are that only one who exchange the value from 0 to 1 - Then the
acquirebarrier means:- anything you do AFTER the barrier is guaranteed to see the memory state of at least how it was at the moment you do that atomic operation.
- You can see the later state of the memory, you just can't see the earlier state.
- Why is it not a problem you can see the later state? What if someone else change, say
x, after you acquire? - Will, that can't happen, as long as everyone takes the lock (or, exchange with acquire) before accessing
x. Soxcan't be changed because of the exclusion that atomic guarantees. - So whatever someone else do to
xbefore the barrier, it's guaranteed to be visible to me. - And nobody can do anything to
xafter the barrier, if everyone correctly acquire the barrier before accessing. - If there is some other thread somewhere accessing without acquiring the lock correctly, then it's all off. Your program has a UB.
- When you want to give up, you can just store 0 as you are the only one who exchange 0 with 1.
- Also, you put the
releasebarrier to ...- guarantee that all the changes you made in between the critical section, will become visible to anybody else who acquire the lock after you.
- Still, the same, only those who do their work to acquire can get such guarantee. If you don't, there is no guarantee about what you will get.

Bidirectional barriers
- Acquire-release (
std::memory_order_acq_rel) combines acquire and release barriers- no operation can move across barrier
- only if both threads use the same atomic variable.
- Sequential consistency (
std::memory_order_seq_cst) removes that requirement and establishes single total modification order of atomic variables.
Why does CAS have two memory orders?
It's because underlying it's like:
bool compare_exchange_strong(T& old_v, T new_v,
memory_order on_success,
memory_order on_failure) {
T tmp = value.load(on_failure);
if (tmp != old_v) { old_v = tmp; return false; }
Lock L;
tmp = value;
if (tmp != old_v) { old_v = tmp; return false; }
value.store(new_v, on_success);
return true;
}C++ memory model caveats
- Hardware platforms have their own memory model (on X86, every load is acquire-load)
- Compiler cannot generate code with weaker memory order, but compiler can do its own reordering.
load()operations may not usestd::memory_order_release(it will compile, but it's UB, according to standard)store()operations may not usestd::memory_order_acquire(it will compile, but it's UB, according to standard)- directly or in combination
std::memory_order_acq_rel
- directly or in combination
std::memory_order_seq_cstis OK even on platforms where it's the same asstd::memory_order_acq_rel- You need acquire-write bidirectional barrier, you have to use
exchange
Default memory order
// std::memory_order_seq_cst (the strongest order)
y = x.load();
x.fetch_add(42);
// same for the overloaded operations
y = x;
x += 42;// can't change the memory order for the operators
// can specify memory order for functions to be weaker than the default
// e.g. can't do
// y = x.load(std::memory_order_acquire)
// x.fetch_add(42, std::memory_order_relaxed)Why change memory order?
- Performance (audience #1: computers)
- Expressing intent (audience #2: other programmers)
- As programmers who address two audiences
Memory barriers and performance

- Memory barriers may be more expensive than atomic operation themselves
- Caution: not all platform provide all barriers, so performance measurements may be misleading
- On x86:
- all loads are acquire-loads, all stores are release-stores
- but adding the other barrier is expensive
- all read-modify-write operations are acquire-release
acq_relandseq_cstare the same thing.
Memory order express programmer's intent
- Lock-free code is hard to write (It's harder to write if you want it work correctly)
- It's also hard to read, so clarity matters (Also to the writer, to reason that it is correct)
- Memory order specification is important to express why the atomic operations are used and what the programmer wanted to happen.
Intention of using std::memory_order_relax
//What you wrote:
std::atomic<size_t> count;
count.fetch_add(1, std::memory_order_relax);What others read:
countis incremented concurrently, not used to index any memory or as a reference count (no other memory access depends on it)- Because if it were, you would want to release or acquire it.
- This is some sort of counter itself
- Note: on x86,
fetch_addis actually memory_order_acq_rel- But note: the compiler could know the difference and reorder some operations across fetch_add
Intention of using std::memory_order_release
//What you wrote:
std::atomic<size_t> count;
count.fetch_add(1, std::memory_order_release);What others read:
countindexes some memory that was prepared by this thread and is now released to other threads ...- I know there should be some data depends on the count, hence we need a release here.
- It could be something like this:
T data[max_count];
initialize(data[count.load(std::memory_order_relax)]); // nobody can see new data yet
count.fetch_add(1, std::memory_order_release); // now they can see itIntention of using ++
//What you wrote:
std::atomic<size_t> count;
++count;What you meant:
- count one of several atomic variables used to access the same memory and kept in sync by some very tricky code.
What others read:
- I have no idea what I am doing but it seems to work; using a lock would probably work just as well but this is way cooler!
Sometimes intent is not easy to express
struct C {
C(const std::vector<int>& v) {
// for some reason, we can't just initialize in member list in one shot
for (x : v) {
if (x > 0) {
++n;
}
}
}
private:
std::atomic<int> n{};
};- Not easy to express because we don't have non-atomic operation on atomics
- For example, by definition, in the constructor, only one thread can see the object that hasn't been constructed yet. Nobody else knows its existence, so why am I using an atomic counter? What am I protecting against?
- Well, I'm not protecting anything, I just can't do anything else.
- Why is constructor doing atomic operations? Can anther thread see the object before it is constructed? You hope not, but sometimes it happens
- How do you express that?
atomic_init(): non-atomic initialization of atomic variablesatomic_ref: make non-atomic object into atomic (C++20)
C++ and std::atomic
- Atomics basically are your memory model made visible.
- They are not always fastest, but they can make code significantly faster.
- And usually if you want to make code explicitly faster, you have to take explicit control of the memory barriers.
- Memory barriers is essential for interaction nof threads through memory, and it significantly affect performance
- Atomic variables and operations on them
- Member function operations (use them) and operators
When to use std::atomic in your C++ code?
- High performance concurrent lock-free data structures (Prove it by measuring performance!)
- Data structures that are difficult or expensive to implement with locks (lists, trees)
- When drawbacks of locks are important (deadlocks, priority conflicts, latency problems)
- When concurrent synchronization can be achieved by the cheapest atomic operations (load and store, or atomic counter)
Parallel algorithms (C++17)
New versions of STL algorithms (not all but some), you might have a new version with extra first argument execution_policy
std::algorithm(execution_policy, ...);where execution policies are:
std::execution::parstd::execution::seqstd::execution::par_unseqstd::execution::unseq(C++20)
Example:
std::vector<double> v;
...// add data to v
std::for_each(std::execution::par, v.begin(), v.end(), [](double& x) { ++x; });Caveat of std parallel algorithm ... compilers are not self-sufficient
- You need to install precisely the right version of Intel Thread Building Blocks (TBB)
- gcc-10 will not use the same TBB as gcc-11
- getting the latest one doesn't make it right for everybody
- same for clang
- Once you get it, note...
- Parallel algorithms do not use C++ own thread machinery
How well is std::algorithm?
- check out code
- very well if there is enough data
- Loop should be long enough
- Each iteration of the loop should be expensive enough
- what is enough depends on algorithm and the library version
If you use parallel STL...
- It's not using pthread but some intel TBB, hardware aware mechanism thread.
- Always measure performance gains for your algorithms and data
- Algorithms that may allocate memory don't scale well
std::vector<double> v(N);
std::vector<double> vv;
vv.reserve(N);
// this copy doesn't scale at all. It actually runs sequentially
copy(execution::par, v.begin(), v.end(), back_inserter(vv));
// but this do:
std::vector<double> vvv(N);
copy(execution::par, v.begin(), v.end(), vvv.begin());
// under the hood, they put some implementation in std::vector so that when the
// execution::par is passed, they know how to separate vector into chunks and do
// the parallelization- Each call uses all available CPUs, concurrent calls to parallel STL algorithms don't run any faster
- Always measure performance gains for your algorithm and data when using std parallel
No control over the granularity of parallelism (done by the library)
- Each call uses all available CPUs?
- The standard does not say anything about the implementation
- Particularly, if you run your own thread on top of the parallel algorithm, you typically don't get more scale because CPU has been exhausted.
- What do the policies do? The policies really define data dependencies between tasks
- Parallel policy implies that the tasks can be executed in any order
- It is up to the programmer to assert the correct policy
- Although it's something, these are likely not the executors you are looking for.
What are unsequenced policies?
- Unsequenced policy allows computations to be interleaved within a single thread, allowing additional optimization such as vectorization.
- Vectorizing compilers do this already, so?...
double much_computing(double x);
vector<double> v; // add data to v
double res = 0;
mutex res_lock;
for_each(execution::par, v.begin(), v.end(), [&](double& x) {
double term = much_computing(x);
lock_guard guard(res_lock);
res += term; // protected by the lock
});- interleaved execution allows one thread to process multiple vector elements at the same time
- processing each element involves acquiring the lock
- one thread acquiring the same lock twice is guaranteed deadlock
- standard term for such operations is vectorization-unsafe
Parallel STL guidelines
- Environment is volatile and performance varies version to version
- Parallel policy is generally very effective
- Needs enough data to give speedup
- Processing large data volumes may be memory-bound
- Output iterators do not parallelize well
- Performance gains vary between algorithms
- some algorithms do not have a parallel version (
std:accumulate) but may have a parallel equivalent
- some algorithms do not have a parallel version (
- Implementation determines which hardware resources are used
- probably does not benefit from higher-level parallelism
- Always measure the impact on performance
- Ideally, both individual algorithms and overall result
Coroutines
- Coroutines are functions that can be interrupted and resumed
- Use of coroutines
- Event-driven programs
- work stealing
- simplify writing asynchronous code
What are coroutines
- Coroutines are functions that can be interrupted and resumed
- In general, there are two types of coroutines:
- stackful coroutines (a.k.a fibers): the state is stored on the stack
- (just like regular functions)
- powerful and flexible
- stackless coroutine: the state is stored on the heap
- no stack frame of their own
- more efficient and lightweight
- stackful coroutines (a.k.a fibers): the state is stored on the stack
- C++20 coroutines are stackless
Stackful v.s. stackless coroutines
Stackful coroutines can be suspended anywhere
- Even after they call other functions
- they resume where they were suspended
Stackless coroutines can be suspended only at the top level
- Once a function is called, it must complete
- They resume where they were suspended (always inside the coroutine body)
- Can call another coroutine which can suspend itself
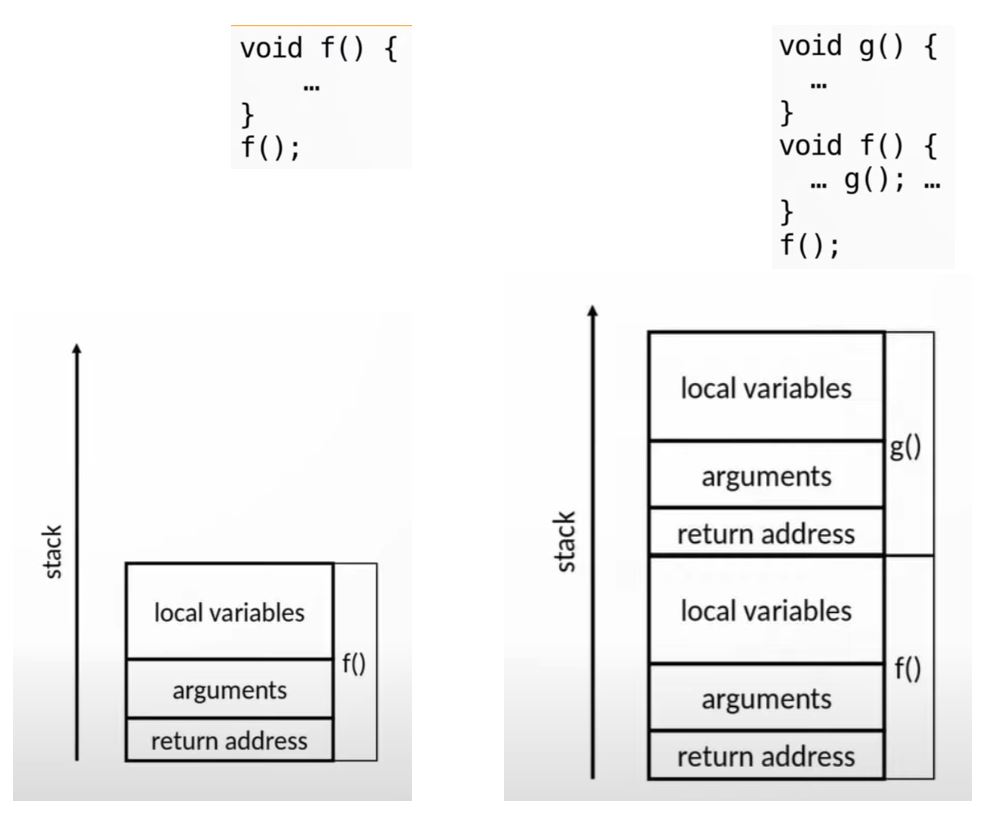
Regular functions stack
Coroutine mechanics
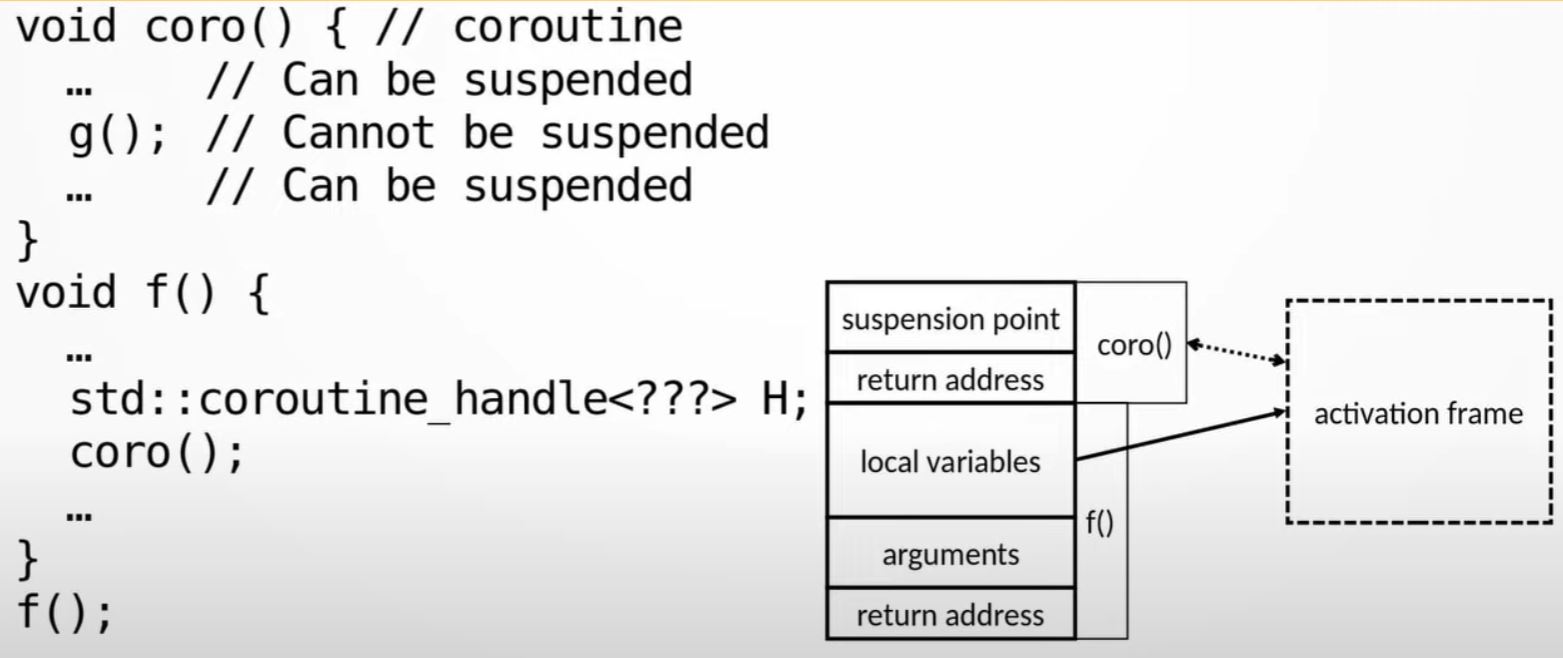
std::coroutine_handle<???>is like a smart pointer that points to something allocated on the heap,, that is called activation frame
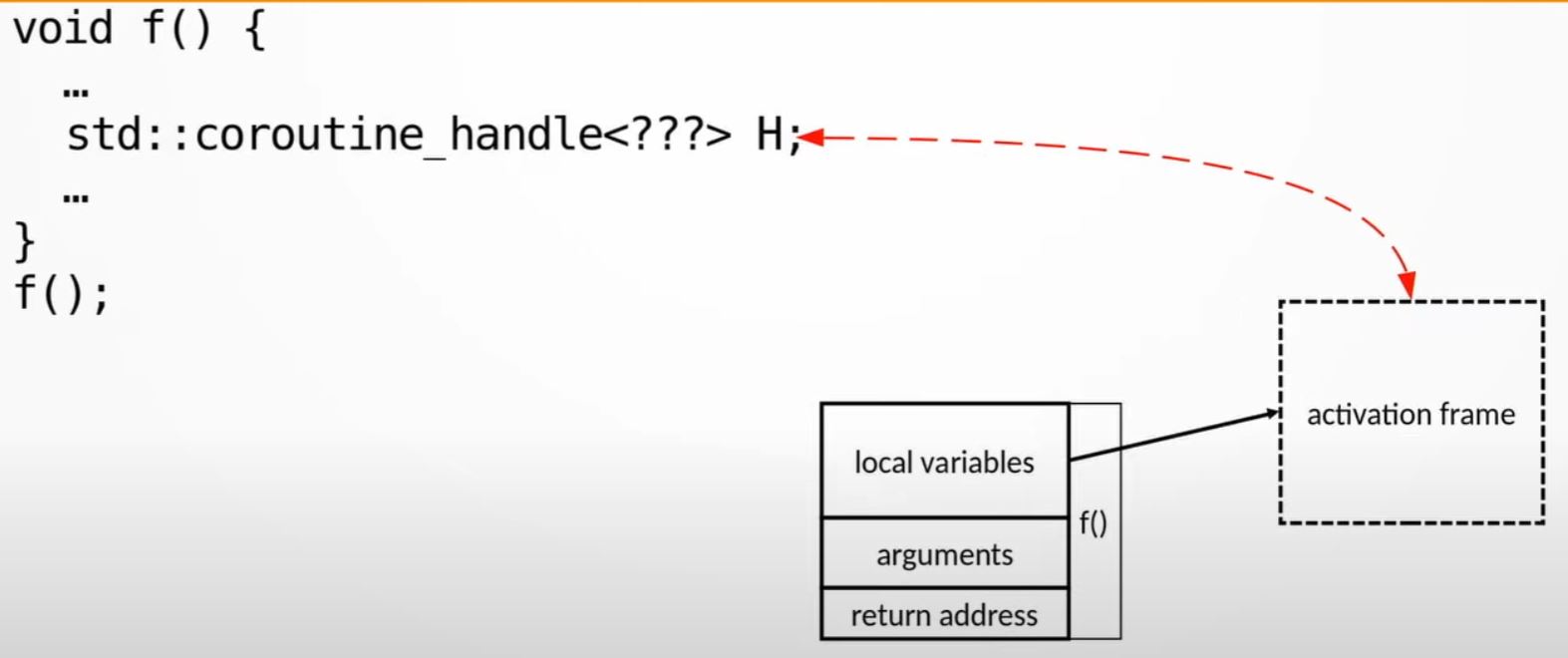
- Note:
corocan be suspended
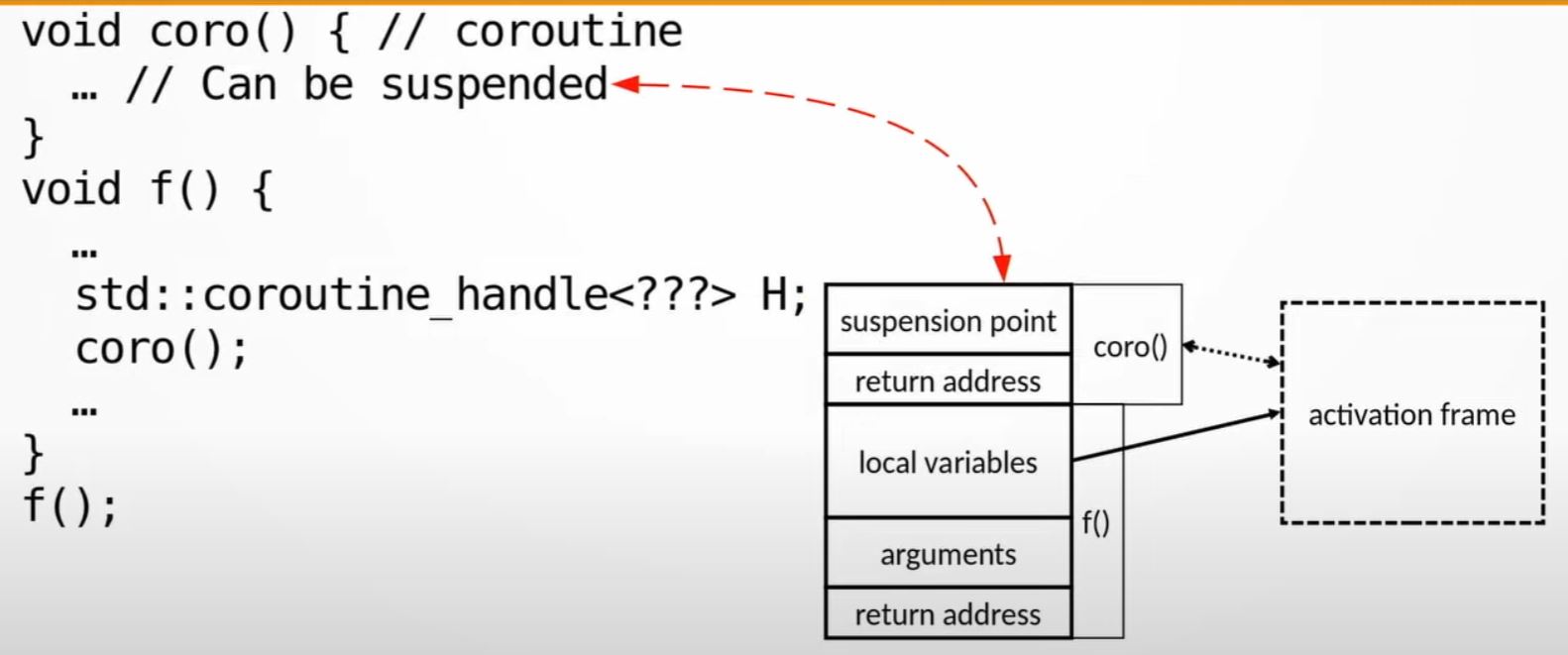
- Note: you can call a regular function
g()from thecoro()coroutine function. But, you lost the ability to suspendcoro()becauseg()is now on the top of the stack, and it doesn't know anything about coroutine. E.g. you can only suspend coroutine from top level of the stack.

What happened if we suspended?
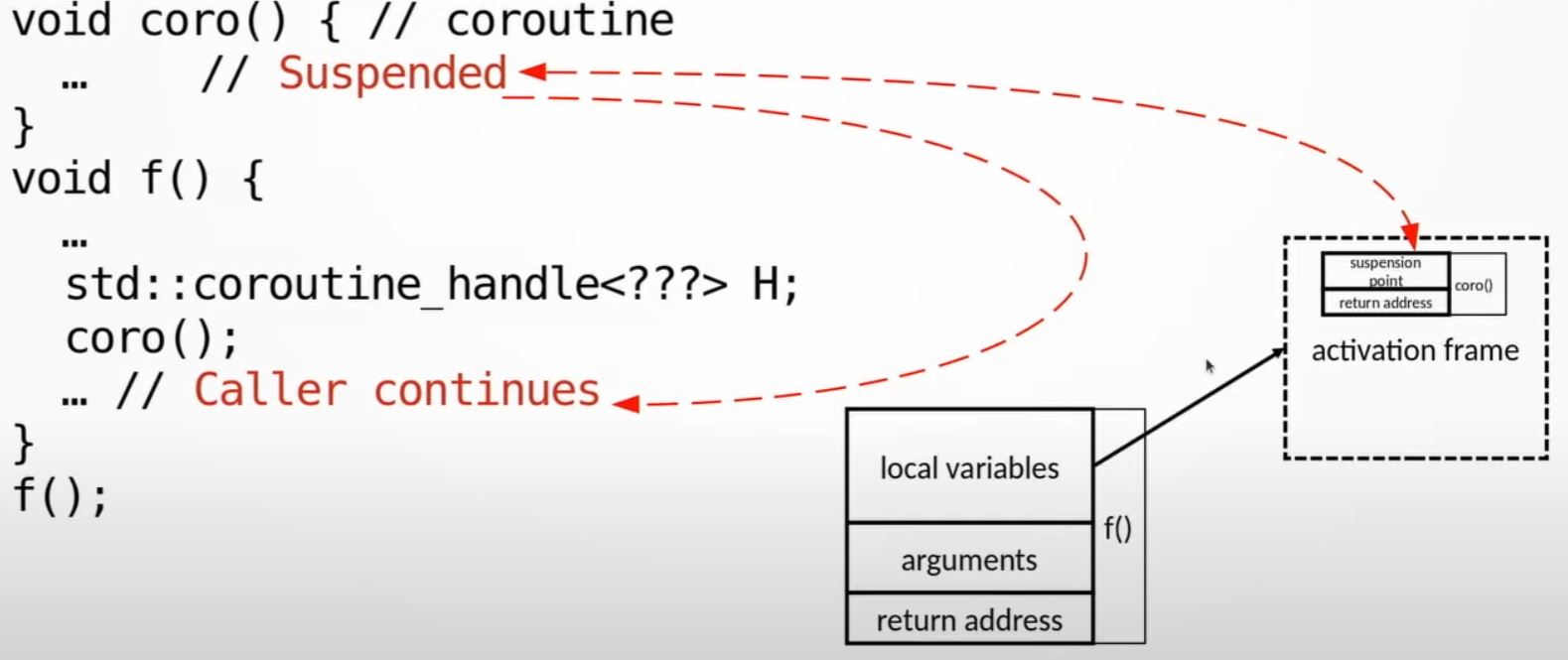
- If we suspended the coroutine, the bit of state that owns the state of the stack are copied into activation frame's suspension point.
- And the control transfers back to the caller.
- The caller has the coroutine handle which can refers to the activation frame.
- The caller keeps running, and the activation frame sits there and coroutine is not running.

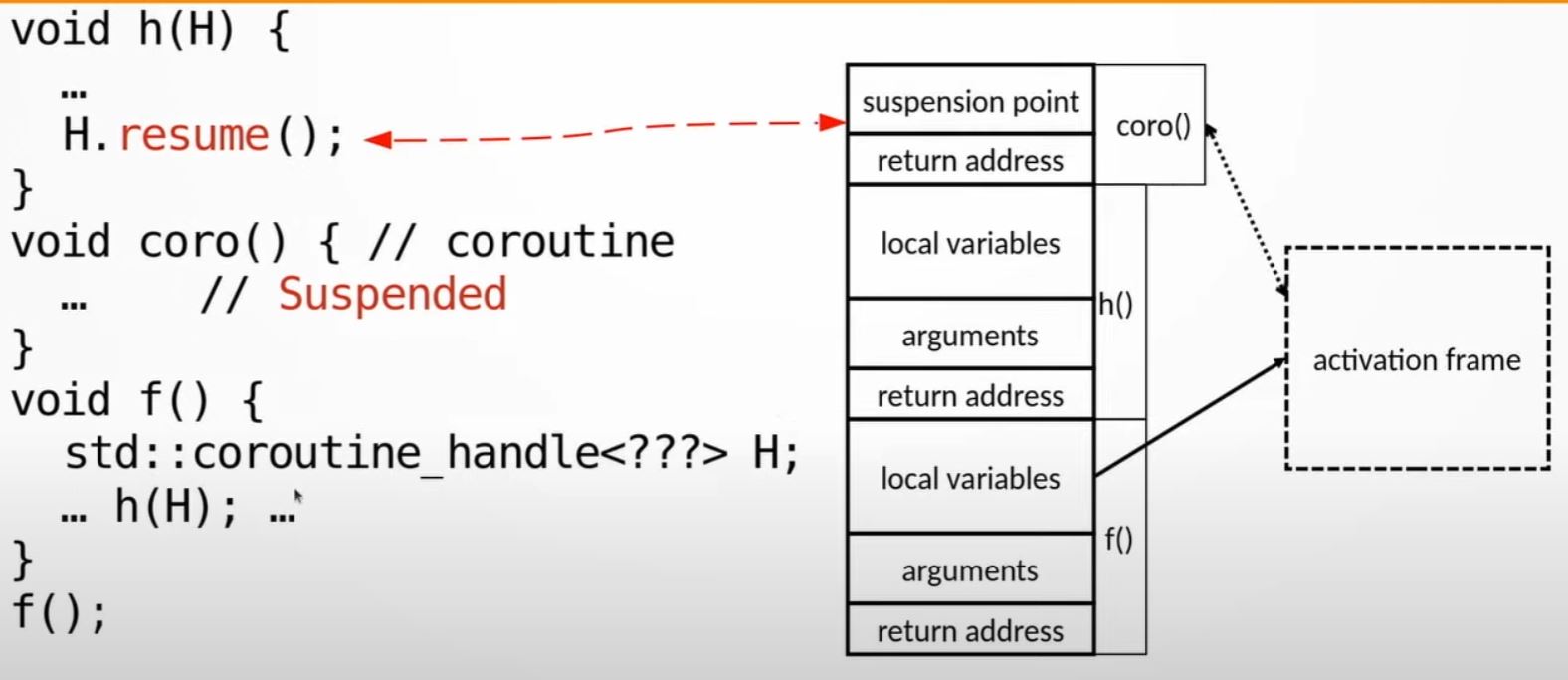
Resumes coroutine
- Anybody having the handle can then resume the coroutine.
- Once
H.resume()is called, the activation frame is accessed through the handle, the stack of coroutine is reconstructed from the activation frame, and coroutine starts running - In the example here, the resumed
His like a child stack ofh(), notg()
- Suspending a coroutine is explicit (cooperative multitasking). Nobody else can suspend coroutine, coroutine has to suspend itself.
- Functions have with stack frames, coroutines have handle objects.
- The lifetime of the coroutine is the lifetime of the handle.
- Coroutine state persists as long as the handle is alive
- The resume can be anywhere (it can even be from other thread)
- After the coroutine is suspended, the control is returned to the caller
- Caller continues to run as if the coroutine had completed
- The coroutine can be resumed from any location
- not just from the caller
- coroutine can even be resumed from a different thread
- coroutine is resumed from the point of suspension and continues to run
Coroutines in C++20
-
Standard:
#include <coroutines> -
GCC:
--std=c++20 -fcoroutines, #include <coroutines> -
MSVC:
/std:c++20, #include <coroutines> -
CLANG-13:
--std=c++20 -stdlib=libc++ -fcoroutines-ts, #include <experimental/coroutines>, namespace std::experimental -
There is no special syntax to declare a coroutine (coroutine is a function)
-
What makes a coroutine a coroutine is suspend by
co_awaitorco_yield -
Coroutines must have specific return types
- The return types are not standard types
- The requirements on the return types are in the standard
- No assistance in the standard library
-
The C++20 standard provides the framework for coroutines
- Without a coroutine library, the code is very verbose (You are not expected to write it more than once)
- Multiple third-party libraries, no standard ones
- Compiler support remains "cutting edge"
-
The standard requires a lot of boilerplate code
-
Coroutines are almost certainly very useful
- We're not exactly sure what for
- Design patterns (recognized solutions to common problems) have not yet emerged in the community
- Likely applications are work stealing, lazy execution, asynchronous execution, and some cool thing we haven't yet thought of.
Coroutine example: Lazy generator
generator<int> // magic return type
coro() {
for (int i = 0;; ++i) {
co_yield i; // return value
// when h(); is called below, it resume to here.
}
}
int main() {
auto h = coro().h_; // handle with reference to activation frame
auto& promise = h.promise();
for (int i = 0; i < 3; ++i) {
std::cout << "result: " promise.value_ /*from magic co_yield*/ << '\n';
h(); // resume coroutine
}
h.destroy();
}generator details
- Name "generator" is not special, most coroutine libraries will have a type like this.
- Must contain nested type "promise_type"
- Maybe a type alias
- Standard lists requirements on promise_type
- Must store the coroutine handle
template <typename T>
struct generator {
struct promise_type {
T value_ = -1;
generator get_return_object() {
using handle_type = std::Coroutine_handle<promise_type>;
return generator{handle_type::from_promise(*this)};
}
std::suspend_never initial_suspend() { return {}; }
std::suspend_never final_suspend() noexcept { return {}; }
void unhandled_exception() {}
std::suspend_always yield_value(T value) {
value_ = value;
return {};
}
void return_void() {}
};
std::coroutine_handle<promise_type> h_;
};Coroutine handle std::coroutine_handle<>
- Is associated with the activation frame
- Is accessed through the return type (Isn't always stored in the return object)
- Callable, invoking the handle resumes the coroutine
- Destroying the handle destroys the coroutine state (activation frame)
Coroutine promise
- Has absolutely nothing to do with std::promise
- Must be named promise_type inside the return type of the coroutine
- Standard defines interface requirements (method names, signatures, and noexcept)
struct promise_type {
X get_return_object();
std::suspend_never initial_suspend();
std::suspend_never final_suspend() noexcept;
void unhandled_exception();
void return_void();
};get_return_object(): constructs return object from the promiseyield_value(T): called byco_yieldto store the return value in the promise objectinitial_suspend(): called the first time coroutine is suspendedfinal_suspend(): called byco_returnreturn_void(): called if the coroutine reaches the endunhandled_exception(): called if an exception escapes the coroutine- The programmer does not call these methods directly, the compiler does.