spso_lock_free_fifo_from_groud_up
Single Producer Single Consumer Lock-free FIFO From the Ground Up - Charles Frasch
Resources
- https://www.boost.org/doc/libs/1_82_0/boost/lockfree/spsc_queue.hpp
- https://github.com/rigtorp/SPSCQueue
- https://www.1024cores.net/home/lock-free-algorithms/queues/unbounded-spsc-queue
- https://www.dpdk.org/
Introduction
Key Characteristics of SPSC FIFO Queues

- Single Producer: Only one thread is responsible for adding (pushing) data to the queue. Attempting to push data from multiple threads leads to undefined behavior.
- Single Consumer: Only one thread is responsible for removing (popping) data from the queue. Similar to the producer, multiple consumers can cause undefined behavior.
- Lock-Free: The queue does not use mutexes or other blocking synchronization mechanisms to ensure mutual exclusion. This characteristic aims to minimize overhead and latency associated with locks.
- Wait-Free: Every operation (push or pop) on the queue guarantees completion in a finite number of steps, regardless of the execution of other threads. This is a stronger condition than lock-free, aiming for maximum responsiveness.
- FIFO (First-In, First-Out): The queue operates on a first-come, first-served basis, where the oldest added element is the first to be removed. This is typically implemented as a circular buffer to efficiently use memory and simplify index management.
Advantages of Using SPSC FIFOs
- Throughput: Breaking down a process into stages (e.g., reading, processing, and writing) and connecting these stages with SPSC FIFOs can significantly improve the overall throughput by parallelizing the work.
- Resilience to Traffic Spikes: By decoupling the stages, the system can better handle sudden increases in workload, as the FIFOs act as buffers that smooth out irregularities in processing demand.
- Simplified Synchronization: The single producer and single consumer constraints simplify the synchronization model, reducing the potential for concurrency bugs and deadlocks.
Disadvantages and Considerations
- Thread Management: Utilizing multiple threads introduces complexity in terms of lifecycle management and coordination.
- Memory Overhead: Each SPSC FIFO requires its own buffer, potentially increasing the application's memory footprint.
- Design Complexity: Designing a system around SPSC queues requires careful consideration of buffer sizes, queue lengths, and the potential for message loss or delays if a queue becomes full.
Circular buffer
Circular FIFO Overview
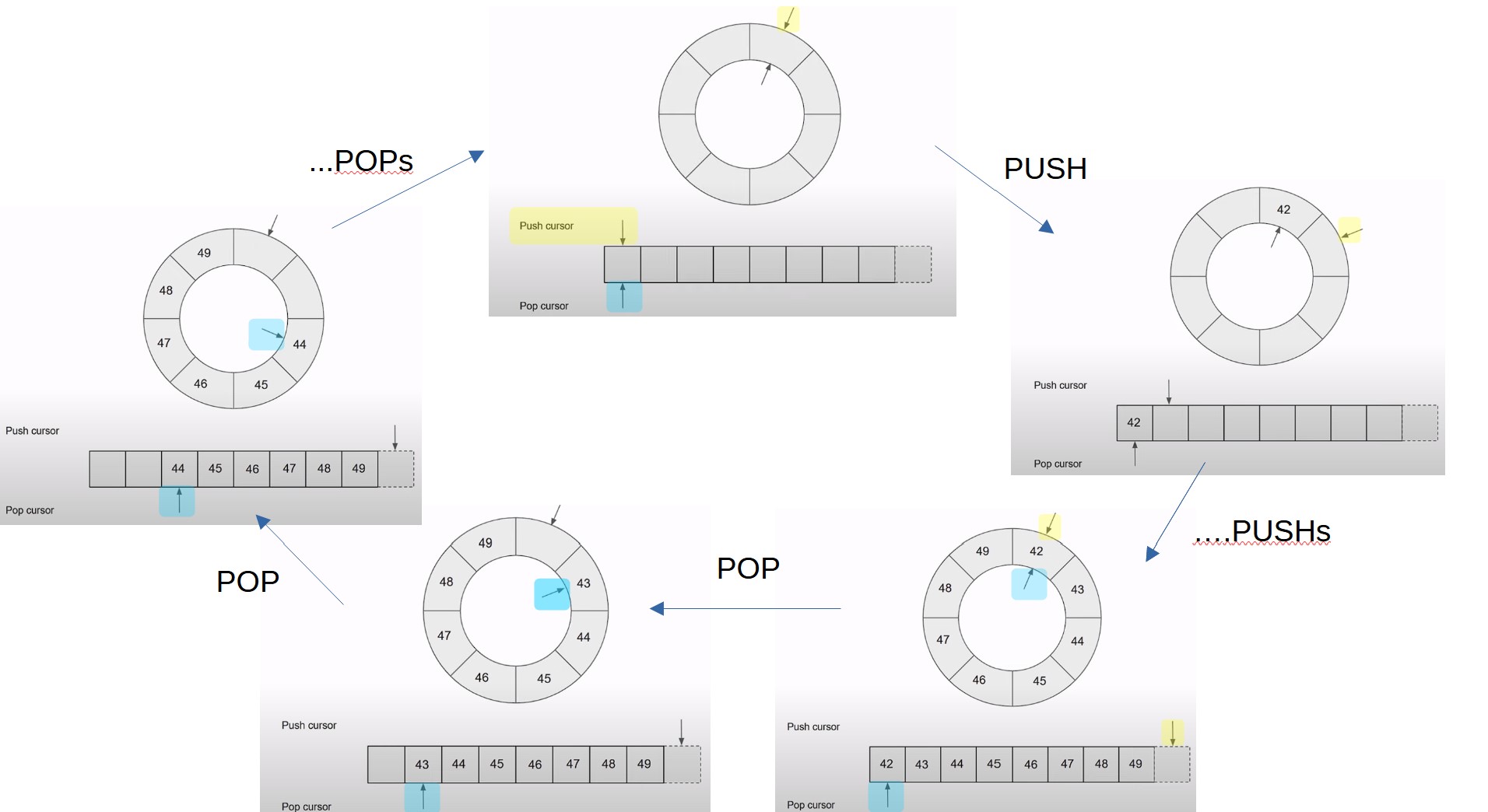
- Structure: A circular FIFO queue is a data structure that uses a fixed-size buffer as if it were connected end-to-end. This allows for efficient utilization of memory and easy management of the queue's capacity.
- Cursors: Two cursors are used to manage the queue:
- Push Cursor: Marks the location where new items are added (pushed) to the queue.
- Pop Cursor: Marks the location from which items are removed (popped) from the queue.
- Empty Queue: Initially, the push and pop cursors are equal, indicating that the queue is empty.
Operation
- Pushing Values: When a value is pushed onto the queue, it is placed at the push cursor's location, and the push cursor is incremented. The queue is no longer empty once values are pushed.
- Popping Values: Popping a value involves reading it from the pop cursor's location and then incrementing the pop cursor. If all values are popped and no new values are pushed, the push and pop cursors become equal again, indicating an empty queue.
Performance Considerations
- Cursor Management: The example uses 64-bit unsigned integers for cursors, allowing for a large range of values. This approach assumes that the system won't run out of cursor values, especially with regular reboots for maintenance.
- Index Calculation: To map the continuously increasing cursor value to an actual index in the array that stores the queue's values, the modulo (remainder) operator can be used. However, this operation can be slow due to division.
- Alternatives:
- Limiting the capacity to a power of two and using bitwise AND for index calculation can significantly improve performance, as it's a much faster operation than division.
- Another method involves constraining the cursor to the array's index range, which also avoids division but requires careful management to prevent overflow.
Implementation 1
template <typename T, typename Alloc = std::allocator<T>>
class Fifo1 : private Alloc {
std::size_t capacity_;
T* ring_;
std::size_t pushCursor_{};
std::size_t popCursor_{};
public:
explicit Fifo1(std::size_t capacity, Alloc const& alloc = Alloc{})
: Alloc{alloc}, capacity_{capacity}, ring_ {
std::allocator_traits::allocate(*this, capacity)
}
~Fifo1() {
while (not empty()) {
ring_[popCursor_ % capacity_].~T();
++popCursor_;
}
std::allocator_traits::deallocate(*this, ring_, capacity_);
}
auto capacity() const { return capacity_; }
auto size() const { return pushCursor_ - popCursor_; }
auto empty() const { return size() == 0; }
auto full() const { return size() == capacity(); }
auto Fifo1::pop(T& value) {
if (empty()) {
return false;
}
value = ring_[popCursor_ % capacity_];
ring_[popCursor_ % capacity_].~T();
++popCursor _;
return true;
}
auto Fifo1 ::push(T const& value) {
if (full()) {
return false;
}
new (&ring_[pushCursor_ % capacity_]) T(value);
++pushCursor _;
return true;
}
};Problem Identification

- Data Races: Identified through thread sanitizer, revealing conflicts in cursor access and element storage between push and pop operations across different threads.
- Undefined Behavior: Arising from data races, leading to unexpected outcomes such as incorrect values being popped from the FIFO.
Solutions and Modifications
/// Loaded and stored by the push thread; loaded by the pop thread
std::atomic<std ::size_t> pushCursor_{};
/// Loaded and stored by the pop thread; loaded by the push thread
std::atomic<std ::size_t> popCursor_{};
static_assert(std: atomic<std::size_t>::is_always_lock_free);- Atomic Cursors: Converting the push and pop cursors to
std::atomic<size_t>types addresses two of the four identified data races by ensuring atomicity in cursor modifications. - Static Assertion for Lock-Freedom: Ensuring atomic operations are lock-free at compile-time with
static_assert, which is crucial for maintaining the FIFO's lock-free property.
Key Concepts
- Atomic Operations: Serve as the backbone for synchronization in multi-threaded environments, enabling lock-free implementations by ensuring operations on shared data are completed atomically.
- Happens-Before Relationship: A concept from the C++ memory model that defines the order in which memory operations appear to be executed, critical for avoiding data races in concurrent programming.
- Lock-Free Programming: Aims to avoid locks and blocking operations, relying instead on atomic operations to manage shared data, enhancing performance and reducing the risk of deadlocks.
Implementation Details
- Cursor Management: Using
std::atomic<size_t>for both push and pop cursors provides a thread-safe mechanism to track the queue's state, automatically solving conflicts related to cursor access. - Ensuring Lock-Freedom: The
static_assertchecks that atomic operations on the cursor types are always lock-free, aligning with the design goals of a lock-free FIFO.
How does atomic change helps
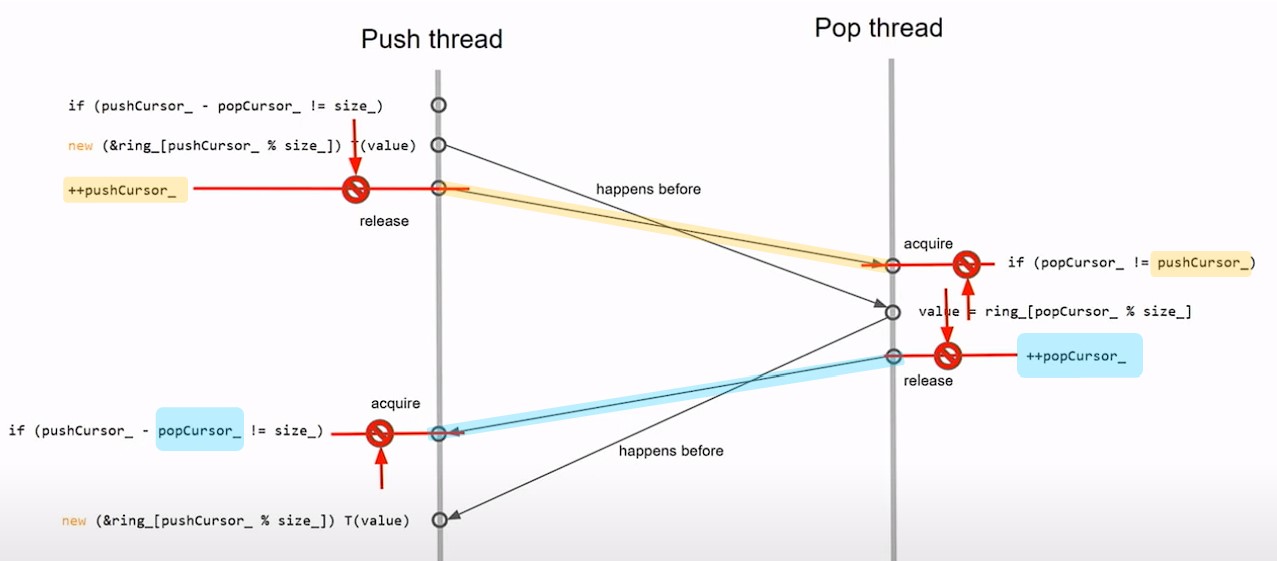
Implementing Atomic Cursors
- Atomic Operations: The push and pop cursors are now
std::atomic<size_t>types, ensuring atomic increments and loads across threads. - Memory Order Semantics: By default, atomic operations are sequentially consistent, which introduces a natural ordering to the operations, ensuring that writes before a store (release) are visible before a subsequent load (acquire) in another thread.
Achieving a Happens-Before Relationship
- Release and Acquire Semantics: The store operation in one thread and the load operation in another thread on the same atomic variable establish a happens-before relationship. This ensures operations before the store are visible to operations after the load, eliminating data races.
- Visibility of Side Effects: The happens-before relationship ensures that all side effects (including non-atomic operations) before the push operation in one thread are visible to the pop operation in another thread, resolving the third data race identified.
!!! KEY of "syncronization"
- those two threads cannot make any assumptions about the start or the flow of time outside their own thread. And to that effect, when we talk about thread synchronization, we literally mean to sync, meaning the same thing, chronos, which is time.
- We're saying that these two threads can understand the same thing about the same moment in time. That's what we mean by thread synchronization.
- To elaborate ...
-
No Assumptions about Time Outside Threads:
- In multithreaded programming, threads operate concurrently and independently. This means that two threads executing simultaneously cannot make any assumptions about when the other thread will start or how it will progress over time.
- Each thread has its own timeline of execution, and the order of operations between threads is not deterministic unless explicitly synchronized.
-
Thread Synchronization and Time:
- When we talk about thread synchronization, we're essentially referring to aligning the execution of threads in such a way that they have a shared understanding of time, or "chronos."
- Synchronization ensures that threads coordinate their activities to achieve certain tasks or share resources without conflicts or race conditions.
-
Understanding the Same Moment in Time:
- Thread synchronization aims to ensure that multiple threads can agree on the progression of time within their shared context.
- By synchronizing threads, we enable them to coordinate their actions based on a common understanding of time, allowing them to cooperate effectively and produce consistent results.
Improvements
alignas(std::hardware_destructive_interference_size)
std::atomic<std ::size_t> pushCursor _;
alignas(std::hardware_destructive_interference_size)
std::atomic<std ::size_t> popCursor _;
/// Padding to avoid false sharing with adjacent objects
char
padding_[std::hardware_destructive_interference_size - sizeof(std::size_t)];
auto full(std::size_t pushCursor, std::size_t popCursor) const {
return (pushCursor - popCursor) == capacity_;
}
//..
auto push(T const& value) {
auto pushCursor = pushCursor_.load(std::memory_order_relaxed);
auto popCursor = popCursor_.load(std::memory_order_acquire);
if (full(pushCursor, popCursor)) {
return false;
}
new (element(pushCursor)) T(value);
pushCursor_.store(pushCursor + 1, std::memory_order_release);
return true;
}
auto pop(T& value) {
auto pushCursor = pushCursor _.load(std::memory_order_acquire);
auto popCursor = popCursor _.load(std::memory_order_relaxed);
if (empty(pushCursor, popCursor)) {
return false;
}
value = *element(popCursor);
element(popCursor)->~T();
popCursor_.store(popCursor + 1, std::memory_order_release);
return true;
}Memory Ordering Optimization
- Relaxed Atomics: For operations solely within one thread (like push in the push thread),
std::memory_order_relaxedis used because these operations don't require memory ordering constraints. They're purely atomic to prevent tearing but don't need to enforce ordering with respect to other memory operations. - Acquire and Release Semantics: For operations involving cross-thread visibility (like when the pop thread needs to see the result of an operation in the push thread),
std::memory_order_acquirefor loads andstd::memory_order_releasefor stores are utilized. This ensures that all operations before a store in one thread become visible before a subsequent load in another thread, establishing a happens-before relationship without the overhead ofstd::memory_order_seq_cst.
Avoiding False Sharing
- Alignment and Padding: To prevent false sharing, which occurs when unrelated variables share the same cache line leading to unnecessary cache coherency traffic, the cursors are aligned to
std::hardware_destructive_interference_size(typically the size of a cache line). Additionally, padding is introduced to ensure that adjacent data does not end up on the same cache line as the cursors.
Implementation Highlights
- Efficient Cursor Management: Cursors are declared with
alignasto ensure they're placed on separate cache lines, effectively eliminating false sharing. The atomic operations on these cursors use specific memory ordering to optimize performance without sacrificing correctness. - Push and Pop Operations: Both operations are fine-tuned to use only the necessary memory ordering. This reduces the overhead compared to default sequentially consistent atomics, leading to significant performance improvements.
Improvement 2
alignas(std::hardware_destructive_interference_size) atomic<std::size_t> pushCursor_;
/// Exclusive to the push thread
alignas(std::hardware_destructive_interference_size) std::size_t cachedPopCursor_{};
alignas(std::hardware_destructive_interference_size) atomic<std::size_t> popCursor_;
/// Exclusive to the pop thread
alignas(std::hardware_destructive_interference_size) std::size_t cachedPushCursor_{};
//..
auto push(T const& value) {
auto pushCursor = pushCursor _.load(std ::memory_order_relaxed);
if (full(pushCursor, cachedPopCursor_)) {
cachedPopCursor_ = popCursor _.load(std : : memory_order_acquire);
if (full(pushCursor, cachedPopCursor_)) {
return false;
}
new (&ring_[pushCursor % capacity_]) T(value);
pushCursor _.store(pushCursor + 1, std ::memory_order_release);
return true;
}
}
auto pop(T& value) {
auto popCursor = popCursor_.load(std::memory_order_relaxed);
if (empty(cachedPushCursor_, popCursor)) {
cachedPushCursor_ = pushCursor_.load(std::memory_order_acquire);
if (empty(cachedPushCursor_, popCursor)) {
return false;
}
}
value = ring_[popCursor % capacity_];
ring_[popCursor % capacity_].~T();
popCursor _.store(popCursor + 1, std ::memory_order_release);
return true;
}- Introduction of Cached Cursors: Each thread (producer and consumer) maintains a cached value of the cursor it primarily reads but doesn't modify (e.g., the push thread caches the pop cursor and vice versa). This strategy reduces the frequency of atomic loads, enhancing performance.
- Condition-Based Cursor Loading: The real cursor values are loaded atomically only when necessary (e.g., when the FIFO is potentially full or empty), ensuring the operation's correctness without compromising efficiency.
Improvement 3
- Potential way to reduce memory copy (though performance isn't clear in the talk)
struct Foo {
int bar;
int blat;
};
static_assert(std::is_implicit_lifetime_v<Foo>); // See P2674R0
Fifo<Foo> fifo(1024);
// called in thread 1
void readAndPushFoo(int sock, Fifo4<Foo>& fifo) {
alignas(Foo) unsigned char buffer[sizeof(Foo)];
::read(sock, buffer, sizeof(Foo));
auto foo = std::start_lifetime_as<Foo>(buffer); // memcpy
if (foo->bar != someValue) throw std ::runtime_error("bad bar");
fifo.push(*foo); // memcpy
}
// called in thread 2
void popAndSendFoo(int sock, Fifo4<Foo>& fifo) {
Foo foo;
if (!fifo.pop(foo)) return; // memcpy
foo.blat = someBlatValue;
::write(sock, std ::addressof(foo), sizeof(Foo)); // memcpy
}- The goal is somehow reduce the
memcpyneeded above
struct Foo {
int bar;
int blat;
...
};
static_assert(std::is_trivial_v<Foo>);
Fifo<Foo> fifo(42);
// called in thread 1
void readAndPushFoo(int rsock, Fifo<Foo>& fifo) {
auto pusher = fifo.push();
::read(rsock, pusher.get(), sizeof(Foo));
if (pusher->bar != someValue) {
pusher.release();
throw std::runtime_error("bad bar");
}
}
// called in thread 2
void popAndSendFoo(int wsock, Fifo<Foo>& fifo) {
auto popper = fifo.pop();
if (!popper) return;
popper->blat = someBlatValue;
::write(wsock, popper.get(), sizeof(Foo)); // memcpy
}- This could be implemented like:
template <typename T, typename Alloc = std::allocator<T>>
class Fifo : private Alloc requires std::is_trivial_v<T> {
// ... same as before
class pusher_t;
pusher_t push();
bool push(T const& value);
class popper_t;
popper_t pop();
bool pop(T* value);
};
class Fifo::pusher_t {
Fifo* fifo_{};
std::size_t cursor_;
public:
pusher_t() = default;
explicit pusher_t(Fifo* fifo, std::size_t cursor)
: fifo_{fifo}, cursor_{cursor} {}
// Not copyable; is movable
~pusher_t() {
if (fifo_) {
fifo_ - > pushCursor_.store(cursor_ + 1, std::memory_order_release);
}
}
explicit operator bool() const { return fifo_; }
void release() { fifo_ = {}; }
T* get() { return fifo_->element(cursor_); }
T const* get() const { return fifo_->element(cursor_); }
T* operator->() { return get(); }
T const* operator->() const { return get(); }
};Fifo::pusher_t Fifo::push() {
auto pushCursor = pushCursor_.load(std : : memory_order_relaxed);
if (full(pushCursor, cachedPopCursor_)) {
cachedPopCursor_ = popCursor _.load(std ::memory_order_acquire);
if (full(pushCursor, cachedPopCursor_)) {
return pusher_t{};
}
return pusher_t(this, pushCursor);
}
bool Fifo::push(T const& value) {
auto pusher = push();
if (pusher) {
*pusher = value;
return true;
}
return false;
}
}Overview of Implementation
-
Fifo Class Enhancements: The
Fifoclass is enhanced with two nested classes,pusher_tandpopper_t, which act as smart pointers that manage access to the FIFO's storage directly. This approach facilitates in-place construction and manipulation of objects within the FIFO, avoiding the need for intermediate copies. -
Read and Push Optimization: For reading from a network socket and pushing objects into the FIFO, the
readAndPushFoofunction utilizes thepusher_tobject to obtain a direct pointer to the FIFO's storage. The network read operation stores data directly into this location, minimizing memory copying. If the read object does not meet specific criteria (e.g.,foo->barcheck), the operation is aborted without altering the FIFO's state. -
Pop and Send Optimization: Similarly, the
popAndSendFoofunction uses thepopper_tobject to directly access and manipulate an object from the FIFO's storage for sending over a network socket. This direct access allows for in-place modifications before the send operation, further reducing memory copying.
Key Features and Considerations
-
Reduced Memory Copies: By allowing direct access to the FIFO's internal storage, the implementation cuts down the number of memory copies required for processing objects, enhancing performance in high-throughput scenarios.
-
Safety and Atomicity: The implementation ensures safety in concurrent environments by managing the FIFO's cursors atomically and by providing mechanisms (
pusher_tandpopper_t) that guarantee atomic updates to the FIFO's state. -
Usage of Trivial Types: The FIFO requires the stored type
Tto be trivial (std::is_trivial_v<T>), ensuring that objects can be safely moved or copied without violating their invariants. -
Smart Pointer-like Accessors:
pusher_tandpopper_tact like smart pointers, offering both direct access to the FIFO's storage and safe management of the FIFO's state, including automatic cursor advancement and resource release mechanisms.
Result
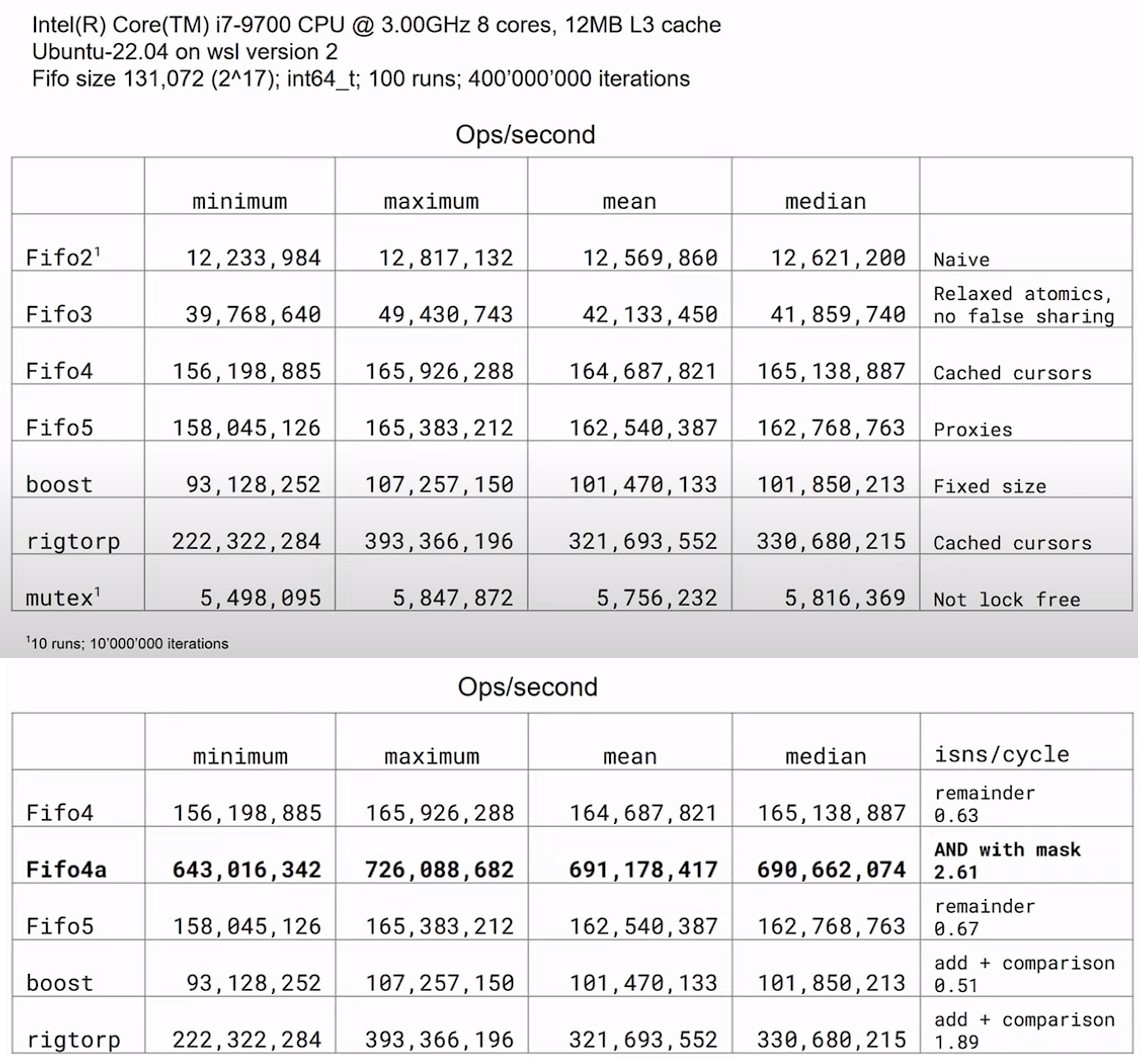
-
Performance of Various FIFO Implementations:
- The Boost Lock-Free SPSC queue, despite being a well-regarded library, shows slightly lower performance compared to a custom FIFO implementation (
FIFO4). This suggests that even highly optimized libraries can sometimes be outperformed by specialized solutions tailored for specific use cases. - Erik Rigtorp's SPSC implementation stands out for its performance, primarily due to avoiding the remainder operation by employing a sentinel element to differentiate between full and empty states of the FIFO. This optimization significantly reduces the computational overhead for each push or pop operation.
- The Boost Lock-Free SPSC queue, despite being a well-regarded library, shows slightly lower performance compared to a custom FIFO implementation (
-
Optimization Techniques:
- Avoiding Remainder Operations: By constraining the FIFO capacity to a power of two and using bitwise AND for index calculation, performance can be notably improved, as demonstrated by the
FIFO4avariant. This approach capitalizes on the efficiency of bitwise operations over more costly arithmetic operations like division or remainder. - Instruction Retirements per Cycle: Performance analysis with tools like
perfreveals that higher instructions per cycle (IPC) correlate with better FIFO performance. This metric is crucial for understanding how efficiently CPU resources are utilized by the FIFO operations.
- Avoiding Remainder Operations: By constraining the FIFO capacity to a power of two and using bitwise AND for index calculation, performance can be notably improved, as demonstrated by the
-
Design Considerations for Lock-Free Queues:
- Choosing the Right Memory Ordering Semantics: The discussion underscores the importance of carefully selecting memory ordering constraints for atomic operations. Reducing the strictness from sequentially consistent to more relaxed models like acquire-release can yield performance benefits without compromising correctness.
- Handling False Sharing: Proper alignment of atomic variables and consideration of cache line sizes are essential to prevent false sharing, which can degrade performance in multithreaded environments.