momory_model
C++ memory model
- Notes taken from
Weak vs. Strong Memory Models
- There are many types of memory reordering, and not all types of reordering occur equally often.
- It all depends on processor you’re targeting and/or the toolchain you’re using for development.
- A memory model tells you, for a given processor or toolchain, exactly what types of memory reordering to expect at runtime relative to a given source code listing
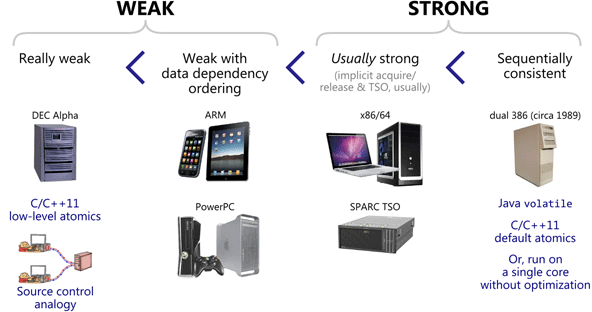
- Each physical device pictured above represents a hardware memory model.
- A hardware memory model tells you what kind of memory ordering to expect at runtime relative to an assembly (or machine) code listing.
- There are software memory models as well. Technically, once you’ve written (and debugged) portable lock-free code in C11, C++11 or Java, only the software memory model is supposed to matter. Nonetheless, a general understanding of hardware memory models may come in handy.
Before C++11 there was only one contract.
- C++ was not aware of the existence of multithreading or atomics.
- The system only knows about one control flow and therefore there were only restricted opportunities to optimize the executable.
- The key point of the system was it, to keep the illusion for the programmer, that the observed behavior of the program corresponds to the sequence of the instructions in the source code.
- Of course, there was no memory model. Instead of that, there was the concept of a sequence point.
- Sequence points are points in the program, at which the effects of all instructions before must be observable.
- The start or the end of the execution of a function are sequence points.
- But in case you invoke a function with two arguments, the C++ standard makes no guarantee, which arguments will be evaluated at first. So the behavior is unspecified.
- The reason is straightforward. The comma operator is no sequence point. That will not change in C++11.
C++11 is the first time aware of multiple threads.
- The reason for the well-defined behavior of threads is the C++ memory model.
- The C++ memory model is inspired by the Java memory model, but the C++ one goes - as ever - a few steps further.
- So the programmer has to obey to a few rules in dealing with shared variables to get a well-defined program.
- The program is undefined if there exists at least one data race.
the C++ memory model defines a contract.
-
This contract is established between the programmer and the system.
- The system consists of the compiler, which compiles the program into assembler instructions, the processor, which performs the assembler instructions and the different caches, which stores the state of the program.
-
The contract requires from the programmer to obey certain rules and gives the system the full power to optimize the program as far as no rules are broken.
-
The result is - in the good case - a well-defined program, that is maximal optimized.
-
Precisely spoken, there is not only a single contract, but a fine-grained set of contracts.
- The weaker the rules are the programmer has to follow, the more potential is there for the system to generate a highly optimized executable.
-
The rule of thumb is quite easy. The stronger the contract, the fewer liberties for the system to generate an optimized executable.
-
In case the programmer uses an extremely weak contract or memory model, there are a lot of optimization choices. But the program is only manageable by a few worldwide known experts.
3 Parts for the contract between the programmer and the system
- Atomic operations: Operations, which will be executed without interruption.
- The partial order of operations: Sequence of operations, which can not be changed.
- Visible effects of operations: Guarantees, when an operation on shared variables will be visible in another thread.
2 levels of the contract in C++11
- from strong to weak
- (strongest) Single threaded: one control flow
- multithreading: tasks/threads/conditional variable
- (weak) atomic: sequential consistency/acquire-release semantic/relaxed semantic
The foundation of the contract are operations on atomics.
- These operations have two characteristics. They are atomic and they create synchronization and order constraints on the program execution.
- These synchronizations and order constraints will often also hold for not atomic operations.
- At one hand an atomic operation is always atomic, but on the other hand, you can tailor the synchronizations and order constraints to your needs.
- With atomics, we enter the domain of the experts. This will become more evident, the further we weaken the C++ memory model.
- Often, we speak about lock-free programming, when we use atomics.
Sequential consistency provides two guarantees.
- The instructions of a program are executed in source code order.
- There is a global order of all operations on all threads.
- Note: The statements only hold for atomics but influence non-atomics.
- Consider below - sequential consistency applies for atomic variable
xandy, but in which order?
t1 t2
x.store(1) y.store(1)
res1 = y.load() res2 = x.load()
- The first guarantee of sequential consistency is that the instruction will be executed in the order of the source code.
- That is easy. No store operation can happens before a load operation in above example
- The second guarantee of sequential consistency is, that all instructions of all threads have to follow a global order.
- That means in that concrete case, that thread 2 sees the operations of thread 1 in the same order, in which thread 1 executes them. This is the key observation.
- Thread 2 sees all operations of thread 1 in the source code order of thread 1.
- The same holds from the perspective of thread 1. So you can think about characteristic 2 as a global counter, which all threads have to obey.
- The global counter is the global order.
- different interleaving executions of the two threads are all possible:
x.store(1) -> res1 = y.load() -> y.store(1) -> res2 = x.load()
x.store(1) -> y.store(1) -> res1 = y.load() -> res2 = x.load()
x.store(1) -> y.store(1) -> res2 = x.load() -> res1 = y.load()
y.store(1) -> res2 = x.load() -> x.store(1) -> res1 = y.load()
y.store(1) -> x.store(1) -> res2 = x.load() -> res1 = y.load()
y.store(1) -> x.store(1) -> res1 = y.load() -> res2 = x.load()
- The programmer uses atomics in this particular example. So he obeys his part of the contract by using them in the right way.
- The system guarantees him a well-defined program behavior without data races.
- In addition to that, the system can execute the four operations in each combination.
From the strong to the weak memory model
-
In case the programmer uses the relaxed semantic, the pillars of the contract dramatically changes.
-
On one hand, it is a lot more difficult for the programmer to apply the contract in the right way. On the other hand, the system has a lot more optimization possibilities.
-
With the relaxed semantic - also called weak memory model - there are a lot more combinations of the four operations possible.
-
The counter-intuitive behavior is, that thread 1 can see the operations of thread 2 in a different order. So there is no picture of a global counter. From the perspective of thread 1 it is possible, that the operation res1 = y.load() happens before x.store(1).
-
Between the sequential consistency and the relaxed-semantic, there are a few more models. The most important one is the acquire-release semantic.
- The acquire-release semantic is the key to a deeper understanding of the multithreading programming because the threads will be synchronized at specific synchronization points in the code.
- Without these synchronization points, there is no well-defined behavior of threads, tasks or condition variables possible.
std::atomic_flag
-
std::atomic_flaghas a simple interface. It's methodclearenables you the set its value to false, withtest_and_setback to true. -
In case you use
test_and_setyou get the old value back. -
To use
std::atomic_flagit must be initialized to false with the constantATOMIC_FLAG_INIT. -
std::atomic_flagis- the only lock-free atomic.
- the building block for higher thread abstractions.
-
The only lock-free atomic?
- The remaining more powerful atomics can provide their functionality by using a
mutex. That is according to the C++ standard. - So these atomics have a method
is_lock_freeto check if the atomic uses internally a mutex. - On the popular platforms, I always get the answer false. But you should be aware of that.
- The remaining more powerful atomics can provide their functionality by using a
-
The interface of a
std::atomic_flagis sufficient to build a spinlock.- check blog post for details.
std::atomic<bool>
std::atomic<bool>has a lot more to offer thanstd::atomic_flag. It can explicitly be set to true or false. That's enough to synchronize two threads
compare_exchange_*
std::atomic<bool>and the fully or partially specializations ofstd::atomicsupports the bread and butter of all atomic operations:bool compare_exchange_strong(T& expected, T& desired).- Because this operation compares and exchanges in one atomic operation a value, is often called
compare_and_swap(CAS).
- Because this operation compares and exchanges in one atomic operation a value, is often called
- A call of
atomicValue.compare_exchange_strong(expected, desired)obeys the following strategy.- In case the atomic comparison of
atomicValuewith expected returns true, the value ofatomicValueis set in the same atomic operation to desired. - If the comparison returns false,
expectedwill be set toatomicValue.
- In case the atomic comparison of
- There is also a method
compare_exchange_weak.- This weak version can spuriously fail.
- That means, although
*atomicValue == expectedholds, the weak variant returns false. - So you have to check the condition in a loop:
while (!atomicValue.compare_exchange_weak(expected, desired)). - The reason for the weak form is performance. On some platforms, the weak is faster than the strong variant.
std::atomic<T*>
- The atomic pointer
std::atomic<T*>behaves like a plain pointerT* - Supports pointer arithmetic and pre-and post-increment or pre-and post-decrement operations
std::atomic<Integral>
- When instantiated with one of the following integral types,
std::atomicprovides additional atomic operations appropriate to integral types such asfetch_add,fetch_sub,fetch_and,fetch_or,fetch_xor, and the composite assignment operators+=,-=,&=,|=and^=.- There is a little difference: the composite assignment operators return the new value, the fetch variations the old value.
Integral:- The character types
char,char8_t(since C++20),char16_t,char32_t, andwchar_t; - The standard signed integer types:
signed char,short,int,long, andlong long; - The standard
unsignedinteger types:unsigned char,unsigned short,unsigned int,unsigned long, andunsigned long long; - Any additional integral types needed by the typedefs in the header
<cstdint>.
- The character types
- There is no multiplication, division and shift operation in an atomic way.
- these operations are relatively seldom needed and can easily be implemented.
template <typename T>
T fetch_mult(std::atomic<T>& shared, T mult) {
T oldValue = shared.load();
while (!shared.compare_exchange_strong(oldValue, oldValue * mult)) { ; }
return oldValue;
}std::atomic<UserDefinedType>
- There are a lot of serious restrictions on a user-defined type to get an atomic type
std::atomic<MyType>. - These restrictions are on the type, but these restrictions are on the available operations that
std::atomic<MyType>can perform. - For
MyTypethere are the following restrictions:- The copy assignment operator for
MyType, for all base classes ofMyTypeand all non-static members ofMyTypemust be trivial.- Note: User-defined copy assignment operators are not trivial. - e.g. Only an automatically by the compiler-generated copy assignment operator is trivial
MyTypemust not have virtual methods or base classes.- MyType must be bitwise comparable so that the C functions
memcpyormemcmpcan be applied.
- The copy assignment operator for
- You can check the constraints on MyType with the function
std::is_trivially_copy_constructible,std::is_polymorphicandstd::is_trivialat compile time. All the functions are part of the type-traits library. - For the user-defined type
std::atomic<MyType>only a reduced set of operations is supported.